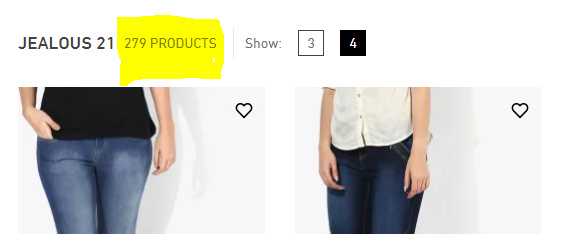
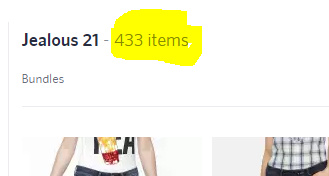
I'm a pretty novice web scraper, but I found this StackOverflow answer that I was able to use to get the results you're looking for. Seems like that second site you are trying to scrape doesn't play well with rvest because it is dynamically created JavaScript and not static HTML.
The basic approach is to start a local Selenium server, navigate to the desired page, and then extract the elements needed. This is done using the RSelenium package from ropensci.
library(RSelenium)
# start up local selenium server
rD <- rsDriver()
remDr <- rD$client
# navigate to desired page
remDr$navigate('https://www.myntra.com/jealous-21')
# access needed element
item_element <- remDr$findElement(using = "xpath", '//*[@id="desktopSearchResults"]/div[1]/section/div[1]/div[1]/span')
# extract element text
items <- item_element$getElementText()[[1]]
# remove non numeric characters
gsub("[^0-9]", "", items)
#> [1] "430"
# close browser
remDr$close()
# stop server
rD[["server"]]$stop()
#> [1] TRUE
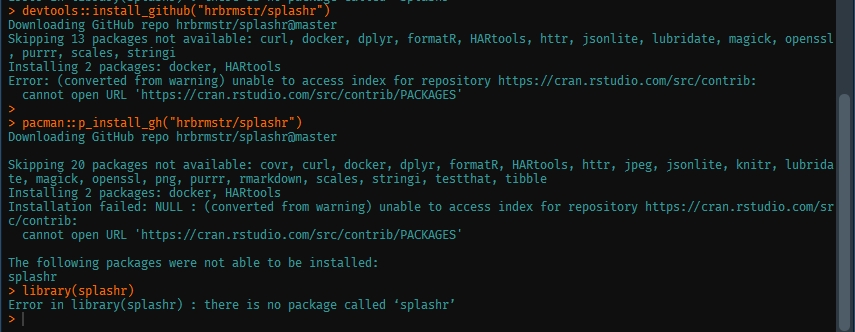
Thank you very much for replying but the code that you wrote doesn't work.
it gives me an error like this
> rD <- rsDriver()
checking Selenium Server versions:
BEGIN: PREDOWNLOAD
BEGIN: DOWNLOAD
BEGIN: POSTDOWNLOAD
Error in .Call(C_serialize_to_yaml, x, line.sep, indent, omap, column.major, :
Incorrect number of arguments (9), expecting 8 for 'serialize_to_yaml'
I read the documentation but it seems like I don't know how to setup the selenium on windows machine. Could you tell me the simplest method to run selenium Please.
Selenium can be tricky; it was not meant as a scraping tool, but as a browser automation tool (the main use case is automated testing - sort of like test_that for web frontends). It is not a simple tool. It requires a browser to run (I used Firefox, which is the default on) and so it is one of the rare use cases when you are better off with a local installation of R Studio than with a server one. Setting up it on a server / in a cloud is possible, but yet more difficult.
It has two modes: Docker and standalone. The docker is supposed to be the preferred way to set it up, but I had more success with standalone installation.
placed it manually in the /bin/ directory of my R package (this was a pretty unusual step!)
created a bat file to start the driver - it has a long name that I found hard to remember and I had difficulties executing it from inside R; this can probably be overcome, but I was lazy...
This needs to be started in CMD console (= outside of RStudio).
java -jar selenium-server-standalone-3.141.0.jar
connected to the driver from your R code by running
RSelenium is not easy to set up, but once you get it running it is a powerful web automation & scraping tool. It actually renders the HTML, meaning pages that do not want to be scraped can run but cannot hide. Use it with caution and respect to the Terms & Conditions of your targets.
I am not a web-scraper by any means, but I have seen people who got stuck with Selenium setup have success with splashr, so that might also be worth a look:
Are you sure you are connected to internet without any proxy required ? This error means the cran url is not reached. Nothing to do with the specific you tried to install.