Does anyone know a non-parametric test for testing the significant difference between slopes?
I have two independent continuous variables divided into three decades (categories). I am specifically looking for a non-parametric test because I am unable to get my data to be normally distributed and their variances are not the same. And I want to find a p-value for each two decades compared, e.g. decades 1 slope to decade 2 slope, decade 1 slope to decade 3 slope, and decade 2 slope to decade 3 slope.
I was able to do this with an ANOVA test using this code:
library(lsmeans) # found code from : https://stats.stackexchange.com/questions/33013/what-test-can-i-use-to-compare-slopes-from-two-or-more-regression-models
d.interaction <- lm(y ~ x*d, data = df)
anova(d.interaction)
#obtain slopes
d.interaction$coefficients
d.lst <- lstrends(d.interaction, "d", var="x")
#compare slopes
pairs(d.lst)
However, I need a non-parametric test. I was told a Kruskal-Wallis test would be the test I need but I cannot for the life of me to find a code that does something similar to this ANOVA code above does (specifically finding a p-values for each decade slope compared to one another). If I have to filter the data to only compare two decade slopes at a time, I'm ok doing that too (I can easily do that with my data).
Does anyone have an idea as to how I can achieve this? If you have any questions or need further explanation, please don't hesitate to ask!
I'll be honest, stats is not my strong suit. Does Kruskal-Wallis test look at the x-y slope, not just the x values?
I want to specifically look at the p-value for each regression comparison, e.g. p-value for D1 - D2, D1 - D3, and D2 - D3. From searching online, I've seen the regression coefficient and constants compared between two slopes but no R coding for it or a non-parametric test.
Sorry for the delay. I'd like to back up from how to what because school algebra, f(x) = y provides a useful framework.
The three objects, f, x, y (in R, everything is an object) are
x, what is at hand, in this case the data frame DF y, what is desired, to discuss f, the function to convert x to y
Objects in R are often composite—in particular, functions are often composed, as in f(g(h)
But, rather than focusing for now on f, let's think about y.
We have a variable within DF, y and we are interested in the association between y and the variables within DFx (continuous) and d (catgegorical). One measure of association is provided by the flm.
Neglecting d for a moment, we can look an ordinary least squares (linear) regression of y on x
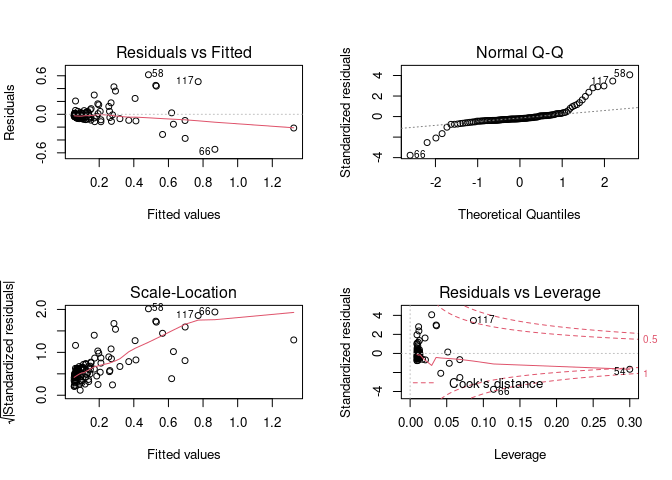
We will take fit at face value, even though the diagnostics show that underlying assumptions of linear regression are unsatisfied for these data. (That's another discussion; here, we are concerned with a different aspect.) If the model did satisfy the requirements, we could read summary(fit) to find
The F-statistic for the model has a vanishingly low probability (p-value) of being observed due to random variation.
The contribution of the x variable, likewise, has a p-value of its test statistic that has an equally low likelihood of being due to random variation.
The line that passes through the points on the x//y axis has a given intercept on the y axis with a slope that can be calculated with the estimate of x
However, this ignores d—the x points can be classified into three d buckets. Does it matter which?
One way to look at it is to add d to the formula in lm. (The following omits DF from the reprex for brevity.)
# USE DF from first reprex
fit <- lm(y ~ x + d, data = DF)
summary(fit)
#>
#> Call:
#> lm(formula = y ~ x + d, data = DF)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -0.57710 -0.05713 -0.02887 0.01338 0.58666
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.0650519 0.0254412 2.557 0.012 *
#> x 0.0069560 0.0005143 13.526 <2e-16 ***
#> dD2 0.0142324 0.0393399 0.362 0.718
#> dD3 -0.0399107 0.0350181 -1.140 0.257
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.1535 on 103 degrees of freedom
#> (13 observations deleted due to missingness)
#> Multiple R-squared: 0.6507, Adjusted R-squared: 0.6405
#> F-statistic: 63.95 on 3 and 103 DF, p-value: < 2.2e-16
In this iteration, the F-statistic p-value indicates that at least one of the parameters is useful compared to a model with no parameters, and the p-values for the t-values show that only x is (the unfortunately named) significant. Knowing whether d is type D2 or D3 provides no useful information.
Likewise for interactions. ( (The following omits DF from the reprex for brevity.)
fit <- lm(y ~ x*d, data = DF)
summary(fit)
#>
#> Call:
#> lm(formula = y ~ x * d, data = DF)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -0.51802 -0.05758 -0.02409 0.01314 0.61053
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.0565518 0.0292031 1.937 0.0556 .
#> x 0.0077897 0.0014898 5.229 9.26e-07 ***
#> dD2 0.0383699 0.0452015 0.849 0.3980
#> dD3 -0.0458228 0.0425569 -1.077 0.2842
#> x:dD2 -0.0014669 0.0016540 -0.887 0.3773
#> x:dD3 -0.0002165 0.0017161 -0.126 0.8999
#> ---
#> Signif. codes: 0 '' 0.001 '' 0.01 '' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.1538 on 101 degrees of freedom
#> (13 observations deleted due to missingness)
#> Multiple R-squared: 0.6562, Adjusted R-squared: 0.6391
#> F-statistic: 38.55 on 5 and 101 DF, p-value: < 2.2e-16
This is similar. We could go on to subset `DF` to include only two of `D1, D2 or D3`, but the results would be similar; the information about **d** provides no insight as to **y**. And neither`anova` nor `aov` are going to help either for the reason alluded to above—the residuals are not normally distributed. (See the `qqplot` in the first `reprex`.)
And *that* is the reason we need a non-parametric test—Kruskal-Wallis is the one we are looking at, but there are [many, many more](https://cran.r-project.org/web/packages/PMCMRplus/vignettes/QuickReferenceGuide.html)
(See the `qqplot` in the first `reprex`.)
``` r
kruskal.test(y ~ d, data = DF)
#>
#> Kruskal-Wallis rank sum test
#>
#> data: y by d
#> Kruskal-Wallis chi-squared = 0.89347, df = 2, p-value = 0.6397
What does this tell us?
kruskal.test performs a Kruskal-Wallis rank sum test of the null that the location parameters of the distribution of x are the same in each group (sample). The alternative is that they differ in at least one.
So, at least one of D1, D2 or D3 has a different location parameter. (We should have seen this coming). The following omits DF from the reprex for brevity.
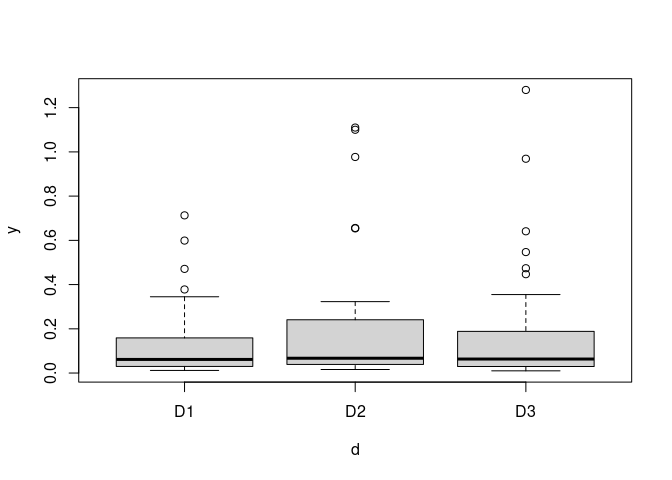
boxplot(y ~ d, data = DF)
In formal terms, we reject the null hypothesis, H_0 that the d groups are the same.
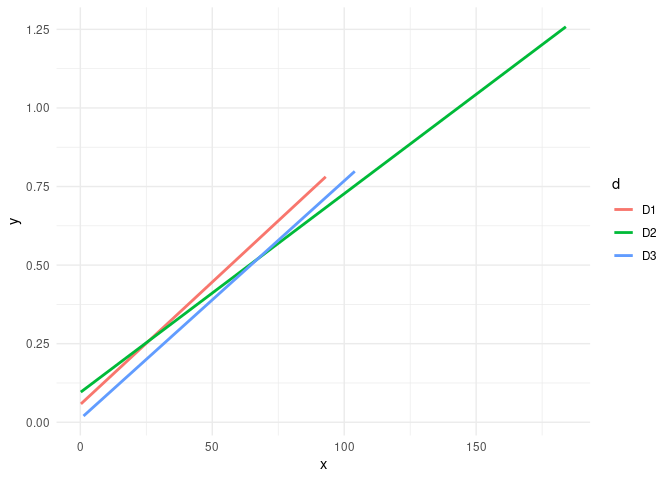
How do we turn this into something we can add to an x-y plot? Not in a way that makes sense unless we want to plot the three lm models of y˜x. Going back to visualization will help. The following omits DF from the reprex for brevity.
ggplot(DF,aes(x,y,color = d)) + geom_smooth(method = "lm", se = FALSE) + theme_minimal()
#> `geom_smooth()` using formula 'y ~ x'
#> Warning: Removed 13 rows containing non-finite values (stat_smooth).