Hey,
I'm fairly new to R and I'm practicing some assignments for my class and I'm struggling with importing and editing my CSV file. I should also note I have to do this without modifying the files outside of R.
I use the read.csv function and then remove the rows I don't need.
All my data including dates end up in 1 column with " , " as separator but I would like to split them into their own columns.
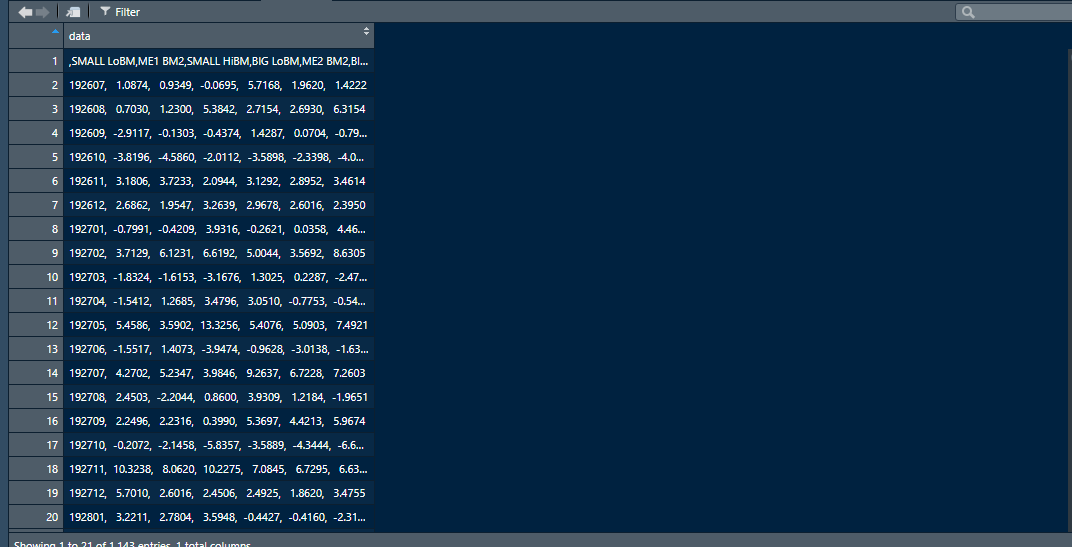
example of 2 rows in my column:" 192607, 1.0874, 0.9349, -0.0695, 5.7168, 1.9620, 1.4222 "
" 192608, 0.7030, 1.2300, 5.3842, 2.7154, 2.6930, 6.3154 "
Here the date comes first and is followed by the 6 pieces of data that are separated with ", " .
I want to have a column for each piece of data and the date. Any help is greatly appreciated!
I tried using the stringr package and the str_split_fixed function but I couldn't seem to get it to work.
My code:
import data from CSV file
data <- read.csv("./6_Portfolios_2x3.CSV", sep=" ; ")
if its a true csv, which has comma seperated values, then using read.csv with sep parameter set to semicolon sep=" ; " is a definite mistake.
the default sep="," should be used.
data <- read.csv("./6_Portfolios_2x3.CSV")
because its the default for the function it can be omitted.
Oh yea sorry should have mentioned. semicolon here is definitely closer to what I want. That way all my data is correctly placed in corresponding rows, although still only in 1 column, while using the default ", " seperator means I only get one piece of data each row. So instead of one row with all data with the corresponding date like:
side note for forum use : to format results in a nice monospace format, use the backtick symbol on your keyboard three times on its own row before the text to format.
> readLines(con=file("./6_Portfolios_2x3.CSV"),n = 6)
[1] "This file was created by CMPT_ME_BEME_OP_INV_RETS using the 202108 CRSP database."
[2] "It contains value- and equal-weighted returns for portfolios formed on ME and BEME."
[3] ""
[4] "The portfolios are constructed at the end of June. BEME is book value at the last fiscal year end of the prior calendar year"
[5] "divided by ME at the end of December of the prior year. "
[6] "Annual returns are from January to December."
Thanks for the forum use tip!
So this is clearly plain text as far as it goes. presumably at some point there is delimited values ? but you should identify on what line that begins. I have here showed the first 6 rows. (n=6)
increase n to the point where it shows your values of interest ideally there are comma seperated heading labels on one row and then rows below are the values, if they are seperated with "," then you will be using that, if they are seperated by another seperator ";" unlikely but possible, then use that.
you can hopefully just use read.csv with an appropriate row skip param.
like if your headings starts on line 23 and values on line 24 then
Huh weird. I've already removed the data I don't need and I've removed the unnecessary text at the top still that command gives me that text as output. Could it be reading from the unmodified file in the working directory perhaps?
Here's a screenshot of how my data looks. From 2 : 1143 (last line) there's only data. The text in row 1 should be the column names and are also separated by " , " .