I have the following dataset.
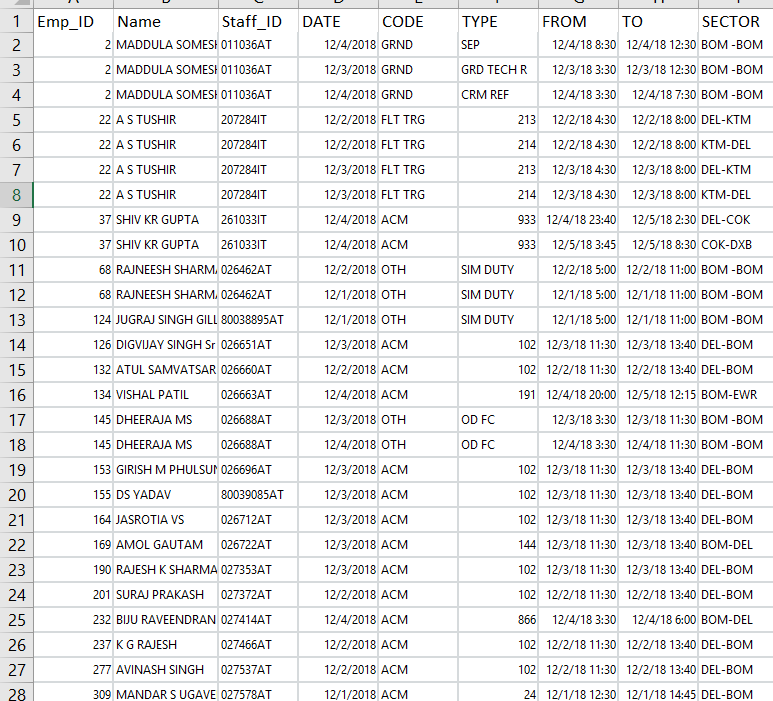
I have concatenated the records using
Emp_Id=c(2,2,2,22,22,22,22,37,37,68,68,124,126,132,134,145,145,153,155,164,169,190,201,232,237,277,309)
Name=c("MADDULA SOMESH BABU", "MADDULA SOMESH BABU", "MADDULA SOMESH BABU", "A S TUSHIR", "A S TUSHIR",
"A S TUSHIR", "A S TUSHIR", "SHIV KR GUPTA", "SHIV KR GUPTA", "RAJNEESH SHARMA",
"RAJNEESH SHARMA", "JUGRAJ SINGH GILL", "DIGVIJAY SINGH Sr", "ATUL SAMVATSAR", "VISHAL PATIL",
"DHEERAJA MS", "DHEERAJA MS", "GIRISH M PHULSUNGE", "DS YADAV", "JASROTIA VS",
"AMOL GAUTAM", "RAJESH K SHARMA", "SURAJ PRAKASH", "BIJU RAVEENDRAN", "K G RAJESH",
"AVINASH SINGH", "MANDAR S UGAVEKAR" )
Staff_ID=c( "011036AT", "011036AT", "011036AT", "207284IT", "207284IT", "207284IT", "207284IT", "261033IT",
"261033IT", "026462AT", "026462AT", "80038895AT", "026651AT", "026660AT", "026663AT", "026688AT",
"026688AT", "026696AT", "80039085AT", "026712AT", "026722AT", "027353AT", "027372AT", "027414AT", "027466AT",
"027537AT", "027578AT")
Date=c("2018-12-04 UTC", "2018-12-03 UTC", "2018-12-04 UTC", "2018-12-02 UTC", "2018-12-02 UTC", "2018-12-03 UTC",
"2018-12-03 UTC", "2018-12-04 UTC", "2018-12-04 UTC", "2018-12-02 UTC", "2018-12-01 UTC", "2018-12-01 UTC",
"2018-12-03 UTC", "2018-12-02 UTC", "2018-12-04 UTC", "2018-12-03 UTC", "2018-12-04 UTC", "2018-12-03 UTC",
"2018-12-03 UTC", "2018-12-03 UTC", "2018-12-03 UTC", "2018-12-03 UTC", "2018-12-02 UTC", "2018-12-04 UTC",
"2018-12-02 UTC", "2018-12-02 UTC", "2018-12-01 UTC")
Code=c("GRND", "GRND", "GRND", "FLT TRG", "FLT TRG", "FLT TRG", "FLT TRG", "ACM", "ACM", "OTH", "OTH",
"OTH", "ACM", "ACM", "ACM", "OTH", "OTH", "ACM", "ACM", "ACM", "ACM", "ACM", "ACM", "ACM", "ACM", "ACM",
"ACM" )
Type=c( "SEP", "GRD TECH R", "CRM REF", "213", "214", "213", "214", "933", "933", "SIM DUTY",
"SIM DUTY", "SIM DUTY", "102", "102", "191", "OD FC", "OD FC", "102", "102", "102",
"144", "102", "102", "866", "102", "102", "024")
From=c("04 Dec 2018 08:30", "03 Dec 2018 03:30", "04 Dec 2018 03:30", "02 Dec 2018 04:30",
"02 Dec 2018 04:30", "03 Dec 2018 04:30", "03 Dec 2018 04:30", "04 Dec 2018 23:40",
"05 Dec 2018 03:45", "02 Dec 2018 05:00", "01 Dec 2018 05:00", "01 Dec 2018 05:00",
"03 Dec 2018 11:30", "02 Dec 2018 11:30", "04 Dec 2018 20:00", "03 Dec 2018 03:30",
"04 Dec 2018 03:30", "03 Dec 2018 11:30", "03 Dec 2018 11:30", "03 Dec 2018 11:30",
"03 Dec 2018 11:30", "03 Dec 2018 11:30", "02 Dec 2018 11:30", "04 Dec 2018 03:30",
"02 Dec 2018 11:30", "02 Dec 2018 11:30", "01 Dec 2018 12:30")
To=c("04 Dec 2018 12:30", "03 Dec 2018 12:30", "04 Dec 2018 07:30", "02 Dec 2018 08:00",
"02 Dec 2018 08:00", "03 Dec 2018 08:00", "03 Dec 2018 08:00", "05 Dec 2018 02:30",
"05 Dec 2018 08:30", "02 Dec 2018 11:00", "01 Dec 2018 11:00", "01 Dec 2018 11:00",
"03 Dec 2018 13:40", "02 Dec 2018 13:40", "05 Dec 2018 12:15", "03 Dec 2018 11:30",
"04 Dec 2018 11:30", "03 Dec 2018 13:40", "03 Dec 2018 13:40", "03 Dec 2018 13:40",
"03 Dec 2018 13:40", "03 Dec 2018 13:40", "02 Dec 2018 13:40", "04 Dec 2018 06:00",
"02 Dec 2018 13:40", "02 Dec 2018 13:40", "01 Dec 2018 14:45")
Sector=c("BOM -BOM ", "BOM -BOM ", "BOM -BOM ", "DEL-KTM", "KTM-DEL", "DEL-KTM", "KTM-DEL",
"DEL-COK", "COK-DXB", "BOM -BOM ", "BOM -BOM ", "BOM -BOM ", "DEL-BOM", "DEL-BOM",
"BOM-EWR", "BOM -BOM ", "BOM -BOM ", "DEL-BOM", "DEL-BOM", "DEL-BOM", "BOM-DEL",
"DEL-BOM", "DEL-BOM", "BOM-DEL", "DEL-BOM", "DEL-BOM", "DEL-BOM")
dataset<-data.frame(Emp_Id,Name,Staff_ID,Date,Code,Type,From,To,Sector)
dataset1<-aggregate(dataset$Date~dataset$Emp_Id+dataset$Name+dataset$Staff_ID+dataset$Sector,data=dataset,paste,sep=",")
dataset1
#> dataset$Emp_Id dataset$Name dataset$Staff_ID dataset$Sector
#> 1 169 AMOL GAUTAM 026722AT BOM-DEL
#> 2 232 BIJU RAVEENDRAN 027414AT BOM-DEL
#> 3 134 VISHAL PATIL 026663AT BOM-EWR
#> 4 2 MADDULA SOMESH BABU 011036AT BOM -BOM
#> 5 68 RAJNEESH SHARMA 026462AT BOM -BOM
#> 6 145 DHEERAJA MS 026688AT BOM -BOM
#> 7 124 JUGRAJ SINGH GILL 80038895AT BOM -BOM
#> 8 37 SHIV KR GUPTA 261033IT COK-DXB
#> 9 126 DIGVIJAY SINGH Sr 026651AT DEL-BOM
#> 10 132 ATUL SAMVATSAR 026660AT DEL-BOM
#> 11 153 GIRISH M PHULSUNGE 026696AT DEL-BOM
#> 12 164 JASROTIA VS 026712AT DEL-BOM
#> 13 190 RAJESH K SHARMA 027353AT DEL-BOM
#> 14 201 SURAJ PRAKASH 027372AT DEL-BOM
#> 15 237 K G RAJESH 027466AT DEL-BOM
#> 16 277 AVINASH SINGH 027537AT DEL-BOM
#> 17 309 MANDAR S UGAVEKAR 027578AT DEL-BOM
#> 18 155 DS YADAV 80039085AT DEL-BOM
#> 19 37 SHIV KR GUPTA 261033IT DEL-COK
#> 20 22 A S TUSHIR 207284IT DEL-KTM
#> 21 22 A S TUSHIR 207284IT KTM-DEL
#> dataset$Date
#> 1 2018-12-03 UTC
#> 2 2018-12-04 UTC
#> 3 2018-12-04 UTC
#> 4 2018-12-04 UTC, 2018-12-03 UTC, 2018-12-04 UTC
#> 5 2018-12-02 UTC, 2018-12-01 UTC
#> 6 2018-12-03 UTC, 2018-12-04 UTC
#> 7 2018-12-01 UTC
#> 8 2018-12-04 UTC
#> 9 2018-12-03 UTC
#> 10 2018-12-02 UTC
#> 11 2018-12-03 UTC
#> 12 2018-12-03 UTC
#> 13 2018-12-03 UTC
#> 14 2018-12-02 UTC
#> 15 2018-12-02 UTC
#> 16 2018-12-02 UTC
#> 17 2018-12-01 UTC
#> 18 2018-12-03 UTC
#> 19 2018-12-04 UTC
#> 20 2018-12-02 UTC, 2018-12-03 UTC
#> 21 2018-12-02 UTC, 2018-12-03 UTC
I want to concatenate the records in such format so that different columns are included in one string.
O/P table
#Emp_Id | Name | Staff_ID | Sector | String containing date & Type/From-to times for that date // second date if there is
2 | MADDULA SOMESH BABU | 011036AT | BOM-BOM | [[2018-12-03UTC "GRD TECH R" 03:30-12:30 // 2018-12-04UTC "CRM REF" 03:30-07:30 / "SEP" 08:30-12:30 ]]#{This is one string/column in a table}
#AND
22 | A S TUSHIR | 207284IT | DEL-KTM | [[2018-12-02UTC "213" 04:30-08:00 //2018-12-03UTC "213" 04:30-08:00
22 | A S TUSHIR | 207284IT | KTM-DEL | [[2018-12-02UTC "214" 04:30-08:00 //2018-12-03UTC "214" 04:30-08:00#{2 records for same Emp_Id but different Sector, string is of same format as above}
Any help and ideas to generate required output or close to the required output is appreciated.
Thank You for your time and concern.
