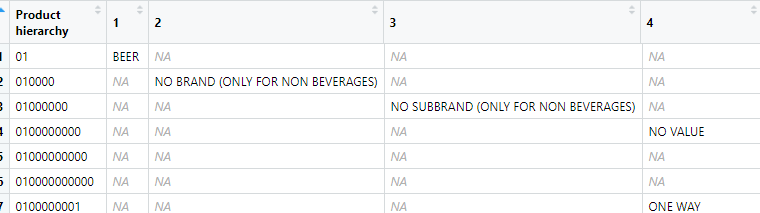
I have two data frames: PH and PH_num created from two excel docs. For PH I did: (see pic for ph output)
ph <- ph %>% pivot_wider(names_from = Number of the level in the product hiera,
values_from = Description,
names_vary = "slowest")
In the PH_num I split out the product hierarchy into multiple different columns. From the picture you can see that 01 equals beer in column 1. What I need to do is:
I would do this sort of thing with a join function. In the example below, I very roughly approximate your data but with fewer columns. I did a left_join which has the property that all the rows of ph_num are returned. If the value of H1 in a row does not exist in ph, then the column X1, the column brought in from ph, will have an NA. Note that if ph had more columns in my example, all of then would be appended to ph_num. You can avoid extraneous columns by making a subset of ph, keeping only the columns that you want to join. You can drop the old D1 column and rename X1 as D1 or you can keep both, whichever works best for your purpose.
library(dplyr)
ph_num <- data.frame(product_hierarchy = LETTERS[1:4],
H1 = c("01", "02", "05", "03"),
D1 = c("wer", "oiuh", "Sdf", "njrv"))
ph <- data.frame(product_hierarchy = c("01", "02", "03", "04"),
X1 = c("BEER", "JUICE", "WATER", "WINE"))
ph_num
#> product_hierarchy H1 D1
#> 1 A 01 wer
#> 2 B 02 oiuh
#> 3 C 05 Sdf
#> 4 D 03 njrv
ph
#> product_hierarchy X1
#> 1 01 BEER
#> 2 02 JUICE
#> 3 03 WATER
#> 4 04 WINE
New_DF <- left_join(ph_num, ph, by = c(H1 = "product_hierarchy"))
New_DF
#> product_hierarchy H1 D1 X1
#> 1 A 01 wer BEER
#> 2 B 02 oiuh JUICE
#> 3 C 05 Sdf <NA>
#> 4 D 03 njrv WATER