Hi,
I need to extract a pdf table (side by side) as shown in the image and save it as a csv. Anybody who could help me here as to how I could do it ? I am using the following code but am unable to do so.
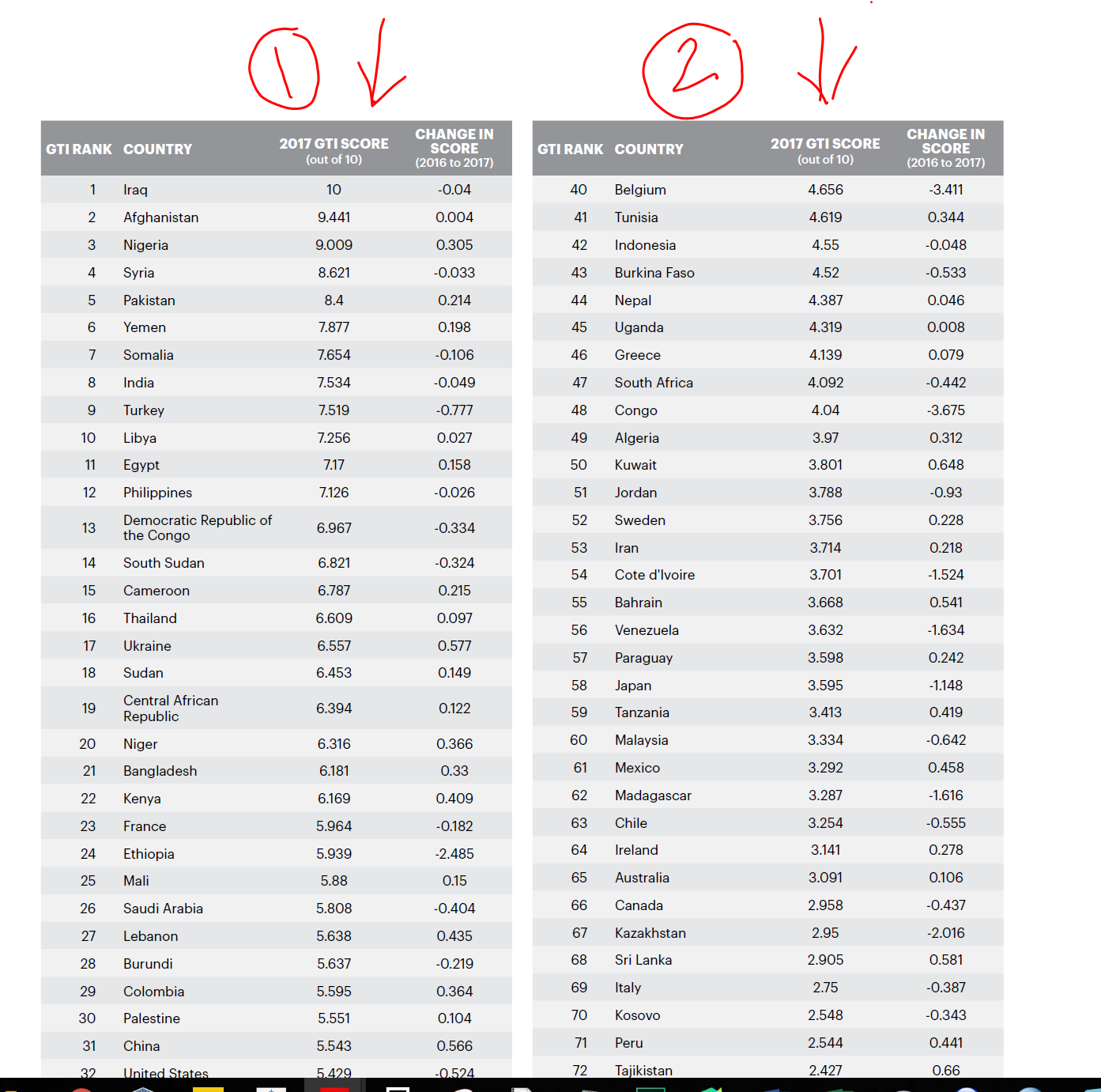
library(tabulizer)
report <- extract_tables("http://visionofhumanity.org/app/uploads/2017/11/Global-Terrorism-Index-2017.pdf", encoding = "UTF-8")
call_data_1 <- report[[25]]
call_data_2 <- report[[26]]
call_data <- rbind(call_data_1)
colnames(call_data) <- as.character(unlist(call_data[1,]))
call_data = call_data[-1, ]
write.csv(call_data, "C:\\my_project\\output1.csv", row.names = FALSE)
call_data2 <- rbind(call_data_2)
colnames(call_data2) <- as.character(unlist(call_data2[1,]))
call_data2 = call_data2[-1, ]
write.csv(call_data2, "C:\\my_project\\output2.csv", row.names = FALSE)
 ... ofcourse the code would be a little longer but customisation is key for me.
... ofcourse the code would be a little longer but customisation is key for me. restarting the RStudio and web-browser worked for me. Strange!
restarting the RStudio and web-browser worked for me. Strange! 