library(dplyr)
set.seed(123)
# Toy data
weight_actual_a = rnorm(50, mean = 10, sd = 4)
weight_actual_b = rnorm(50, mean = 4, sd = 2)
weight_expected_a = rnorm(50, mean = 10, sd = 1)
weight_expected_b = rnorm(50, mean = 4, sd = .2)
df <- tibble(
product = rep(c("A", "B"), each = 50),
weight_actual = c(weight_actual_a, weight_actual_b),
weight_expected = c(weight_expected_a, weight_expected_b)
) %>%
# difference between actual and expected weights
mutate(difference = weight_expected - weight_actual)
head(df)
#> # A tibble: 6 x 4
#> product weight_actual weight_expected difference
#> <chr> <dbl> <dbl> <dbl>
#> 1 A 7.76 9.29 1.53
#> 2 A 9.08 10.3 1.18
#> 3 A 16.2 9.75 -6.48
#> 4 A 10.3 9.65 -0.630
#> 5 A 10.5 9.05 -1.47
#> 6 A 16.9 9.95 -6.91
tail(df)
#> # A tibble: 6 x 4
#> product weight_actual weight_expected difference
#> <chr> <dbl> <dbl> <dbl>
#> 1 B 6.72 3.74 -2.98
#> 2 B 2.80 4.40 1.60
#> 3 B 8.37 4.12 -4.25
#> 4 B 7.07 3.75 -3.32
#> 5 B 3.53 3.88 0.349
#> 6 B 1.95 3.76 1.82
Based on the variable difference and by taking the product group into account, how do I mutate a variable, say, outlier, which will take the value "yes" if the corresponding value is an outlier otherwise "no"?
@FJCC Thank you for your reply. I understand that there is no rigid mathematical definition of what constitutes an outlier. So, I should have been more specific. But, I am not also sure what method would be appropriate. For learning's sake, suppose that I am looking for outliers based on Tukey's method.
Just to clarify, I am trying to find out whether weight_actual and weight_expected differ significantly. As a beginner, I am still trying to find a way to tackle this issue. What do you suggest?
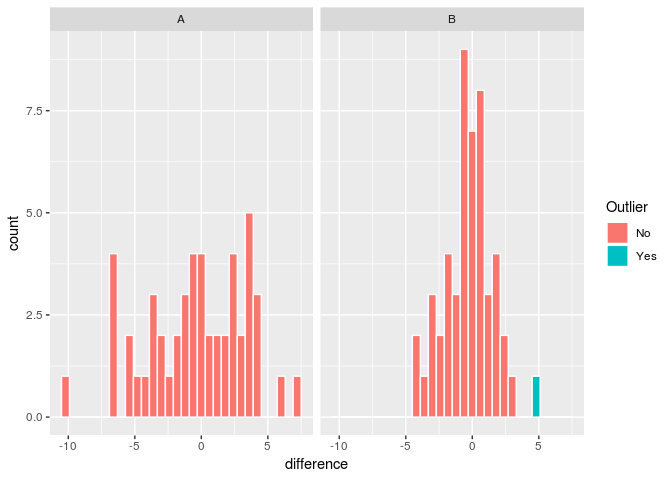
I show a way to use 1.5 * IQR to flag points outside of those limits in the code below. However, I would be very cautious about eliminating data on the basis of such a test. As the data in your reprex show, the differences calculated from normally distributed data with only 50 points can exceed these limits. In a large normally distributed data set, there will almost always be data beyond 1.5 * IQR. And your data may not be normally distributed. My own practice is to keep data unless a definite problem is known (e. g. an instrument is found to be out of calibration) or the data are physically extremely implausible (e. g. a person who weighed 50 kg last month is recorded as weighing 100 kg this month).