Hi @anon12605616 and welcome to RStudio Community.
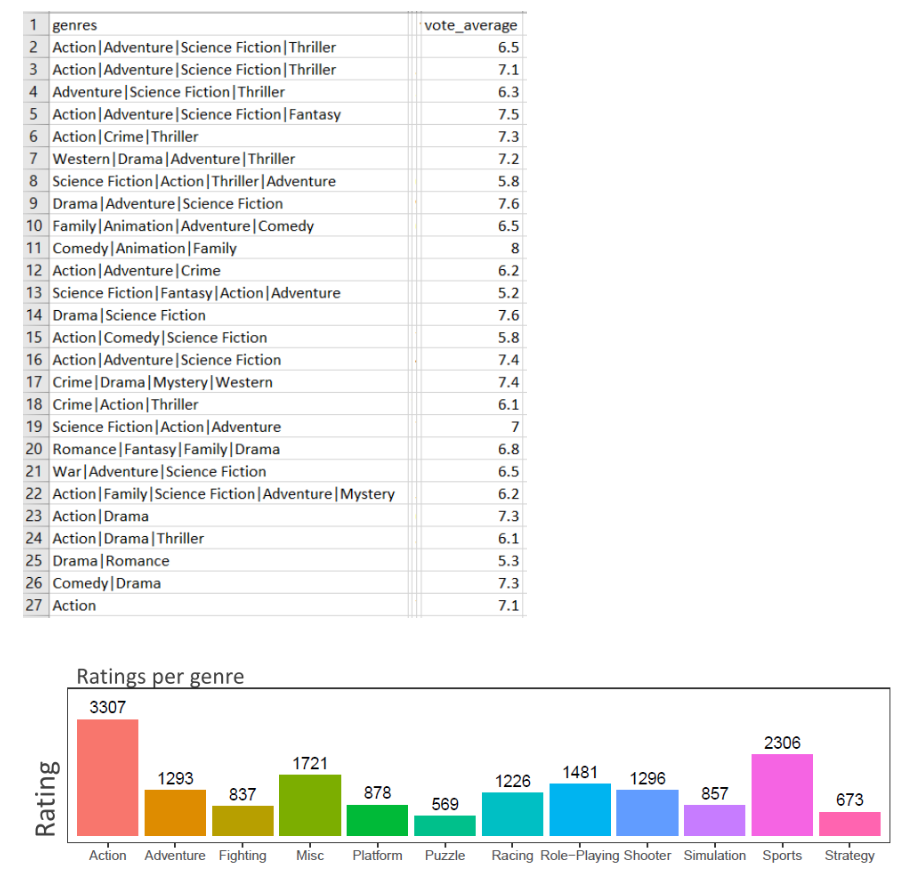
What you are trying to achieve is actually very possible to do in R; however, I am not very sure about what value the barchart represents. The title of the chart is "Ratings per genre", but the values are in the hundreds and the thousands. Are these counts (how many times the genre showed up in the dataset)? Or something else?
In any case, I would also like to suggest that we, in the RStudio Community, are more than happy to provide our help. But we need you to help us too. For example, it would have been great if you provided your dataset, this way all potential helpers would just have to write code and send it to you. You posted a picture, which helps to know what the data look like; however, it cannot really be sliced and diced. I hope you understand what I mean.
I simulated a dataset for you:
library(dplyr)
library(purrr)
set.seed(123)
genres <- c("Action", "Adventure", "Science Fiction", "Thriller", "Western", "Drama", "Crime", "Comedy")
movie_data <- tibble(
genres = map_chr(sample(5, 50, replace = TRUE), function(x){
sample(genres, size = x, replace = FALSE) %>%
paste(collapse = "|")
}),
vote_average = runif(length(genres), 0, 10)
)
movie_data
# A tibble: 50 x 2
genres vote_average
<chr> <dbl>
1 Crime|Action|Adventure 5.31
2 Thriller|Crime|Comedy 7.85
3 Drama|Comedy 1.68
4 Science Fiction|Drama 4.04
5 Drama|Crime|Action 4.72
6 Drama|Adventure|Action|Crime|Thriller 8.68
7 Western|Comedy|Drama|Science Fiction 9.26
8 Action 8.82
9 Thriller|Drama 6.74
10 Action|Drama|Comedy 9.50
# … with 40 more rows
The function you are looking for is the separate_rows() function from the {tidyr} package. It does all the work for you.
library(tidyr)
movie_data_separated <- movie_data %>%
separate_rows(genres, sep = "\\|")
# A tibble: 145 x 2
genres vote_average
<chr> <dbl>
1 Crime 5.31
2 Action 5.31
3 Adventure 5.31
4 Thriller 7.85
5 Crime 7.85
6 Comedy 7.85
7 Drama 1.68
8 Comedy 1.68
9 Science Fiction 4.04
10 Drama 4.04
# … with 135 more rows
The final transformation step is to group_by() genres and then aggregate the vote averages in a way you see fit (hence my question earlier). Here, I just compute the average:
movie_data_by_genre <- movie_data_separated %>%
group_by(genres) %>%
summarize(vote_average = mean(vote_average, na.rm = TRUE))
movie_data_by_genre
# A tibble: 8 x 2
genres vote_average
<chr> <dbl>
1 Action 5.73
2 Adventure 4.26
3 Comedy 5.08
4 Crime 4.56
5 Drama 5.21
6 Science Fiction 4.15
7 Thriller 4.53
8 Western 4.40
The data is now in good shape for visualization with a bar chart:
library(ggplot2)
ggplot(data = movie_data_by_genre, aes(x = genres, y = vote_average)) +
geom_col(aes(fill = genres)) +
theme_classic()
Here, I give you the full code that you need:
library(dplyr)
library(purrr)
library(tidyr)
library(ggplot2)
set.seed(123)
genres <- c("Action", "Adventure", "Science Fiction", "Thriller", "Western", "Drama", "Crime", "Comedy")
movie_data <- tibble(
genres = map_chr(sample(5, 50, replace = TRUE), function(x){
sample(genres, size = x, replace = FALSE) %>%
paste(collapse = "|")
}),
vote_average = runif(length(genres), 0, 10)
)
movie_data
movie_data_by_genre <- movie_data %>%
separate_rows(genres, sep = "\\|") %>%
group_by(genres) %>%
summarize(vote_average = mean(vote_average, na.rm = TRUE))
ggplot(data = movie_data_by_genre, aes(x = genres, y = vote_average)) +
geom_col(aes(fill = genres)) +
theme_classic()