I've been having my doubts on the topic of interpretation of margin plots for missing data.
Package VIM provides with the margin function that outputs the following graph:
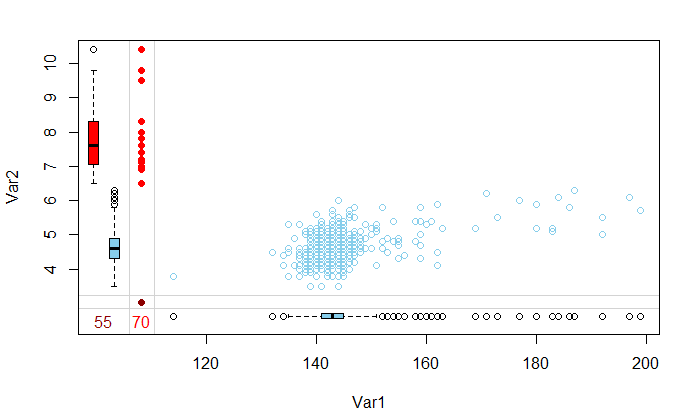
Basically it displays the distribution of one variable's missing data in the other variable (Red) and the distribution of non-missing data as well (blue).
My current decision rule is the following:
-
If the distribution of missing data matches the distributions of non-missing data it means that I can use one variable to input the other.
-
However, if the distributions are different (Var2 in the image), I could not use the other variable (Var1) to input values of the first (Var1). If I did so I would be extrapolating predictions.
-
If the missing data in Var2 is also Missing in Var1 (as it is on the image) I can't use Var2 to input Var1 because the missing data could be MNAR, and in such case, I would be over (or under) estimating the inputted values.
I'm concerned as to whether these decision rules are precise or not.