Please provide some sample data (showing all variables and several examples) and some more details on what your goal is with the analysis. The choice of clustering method really depends on the type of input you have, the number of samples, the correlation between variables, ...
Hi,
my goal is to run several methods of cluster analysis with those methods following different approaches. If as you say there are clustering methods for categorical variables that depend on the type of input, number of samples, correlation, etc please let me know those methods, that is what I'm trying to ask.
Categorical variables are restrictive enough, they are defined as
A categorical variable is a category or type. For example, hair color is a categorical value or hometown is a categorical variable. Species, treatment type, and gender are all categorical variables.
A categorical variable can be expressed as a number for the purpose of statistics, but these numbers do not have the same meaning as a numerical value* . For example, if I am studying the effects of three different medications on an illness, I may name the three different medicines, medicine 1, medicine 2, and medicine 3. However, medicine three is not greater, or stronger, or faster than medicine one. These numbers are not meaningful.
Please let me know if you are aware of methods or strategies for clustering these types of variables.
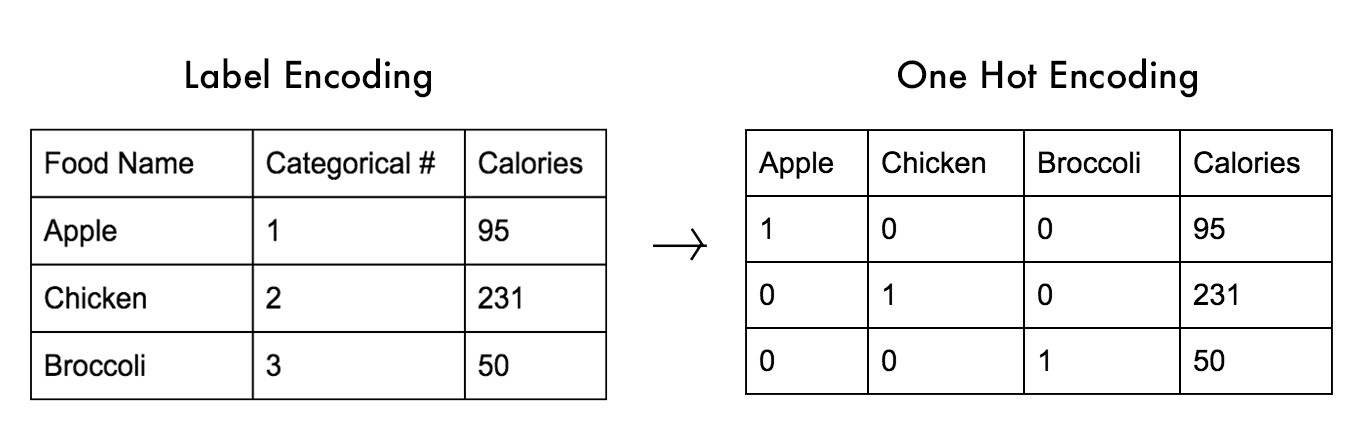
One way of opening the data up for all different types of clustering is by converting the categorical variable into a one-hot vector representation, where you add columns to your data, one for each option in each category:
Although it can greatly expand the input space of the data, then you can use almost any type of clustering method.
THere are many clustering algorithms but one of the most popular methods is k-means clustering for which there are R packages.
Another popular method is hierarchical clustering, were each point is shown in a hierarchy, where you can see how closely it is related to any other point.