Hello,
I have one very large table, and within it are multiple rows of the same ID number all with different data in columns (some have multiple data in the same columns that need to be added together). I need to merge all of each ID number into one row for each one, with the sum of all data in each column going across.
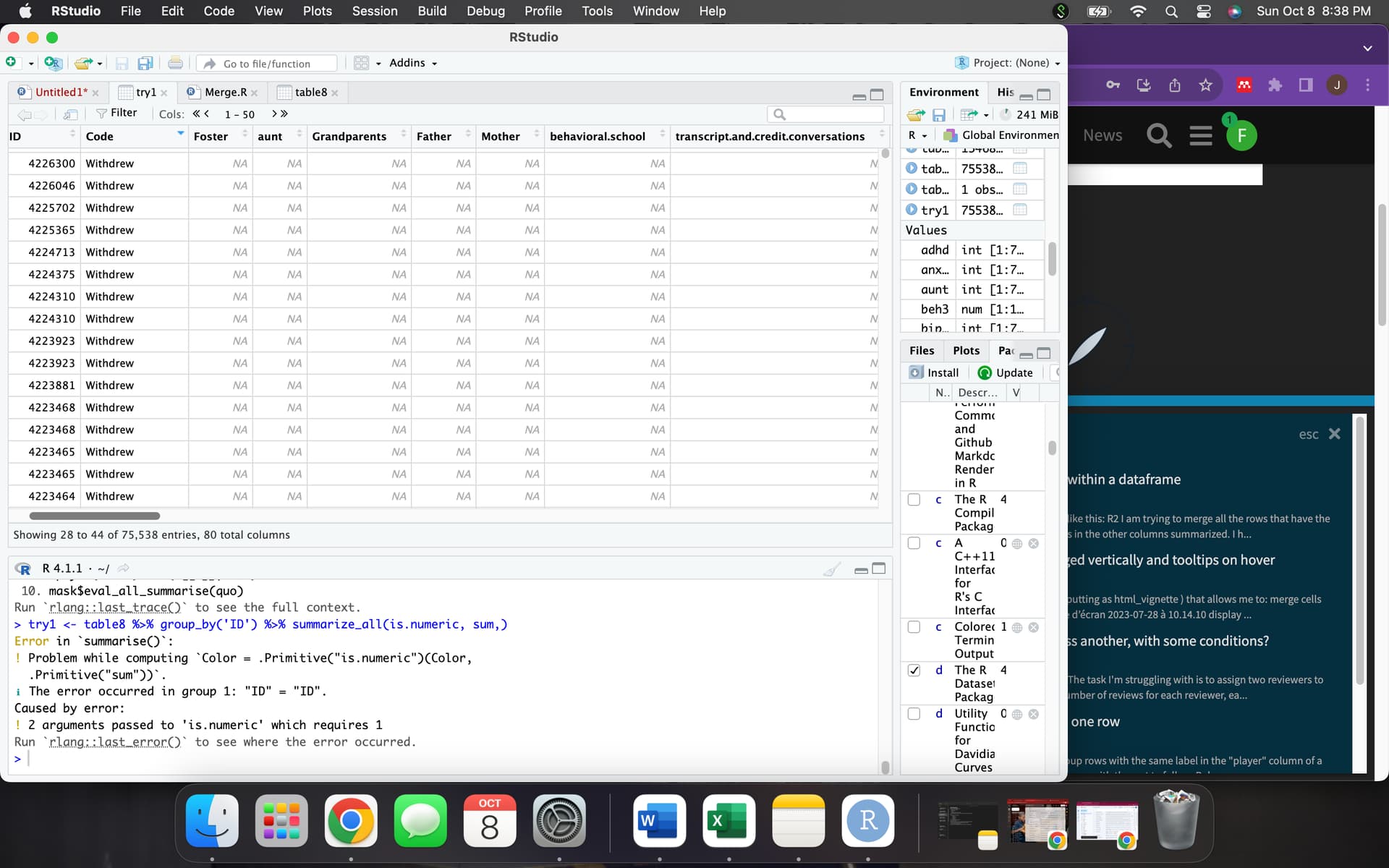
I have tried using merge() and that has not worked. I also tried the code try1 <- table8 %>% group_by('ID') %>% summarize_all(is.numeric, sum, .groups="drop") and that just added all values into one row without separating out the different ID's.
@fletcj3 I am creating a reproducible example here to demonstrate my solution to your question. I hope you find this helpful. If have any further questions, please let me know.
Hi! Thank you for your help, I really appreciate it. Sadly the codes did not do anything. I have attached a screenshot to show you the response I got from R. I copied your codes exactly. Any further advice?
Thank you!
Hi,
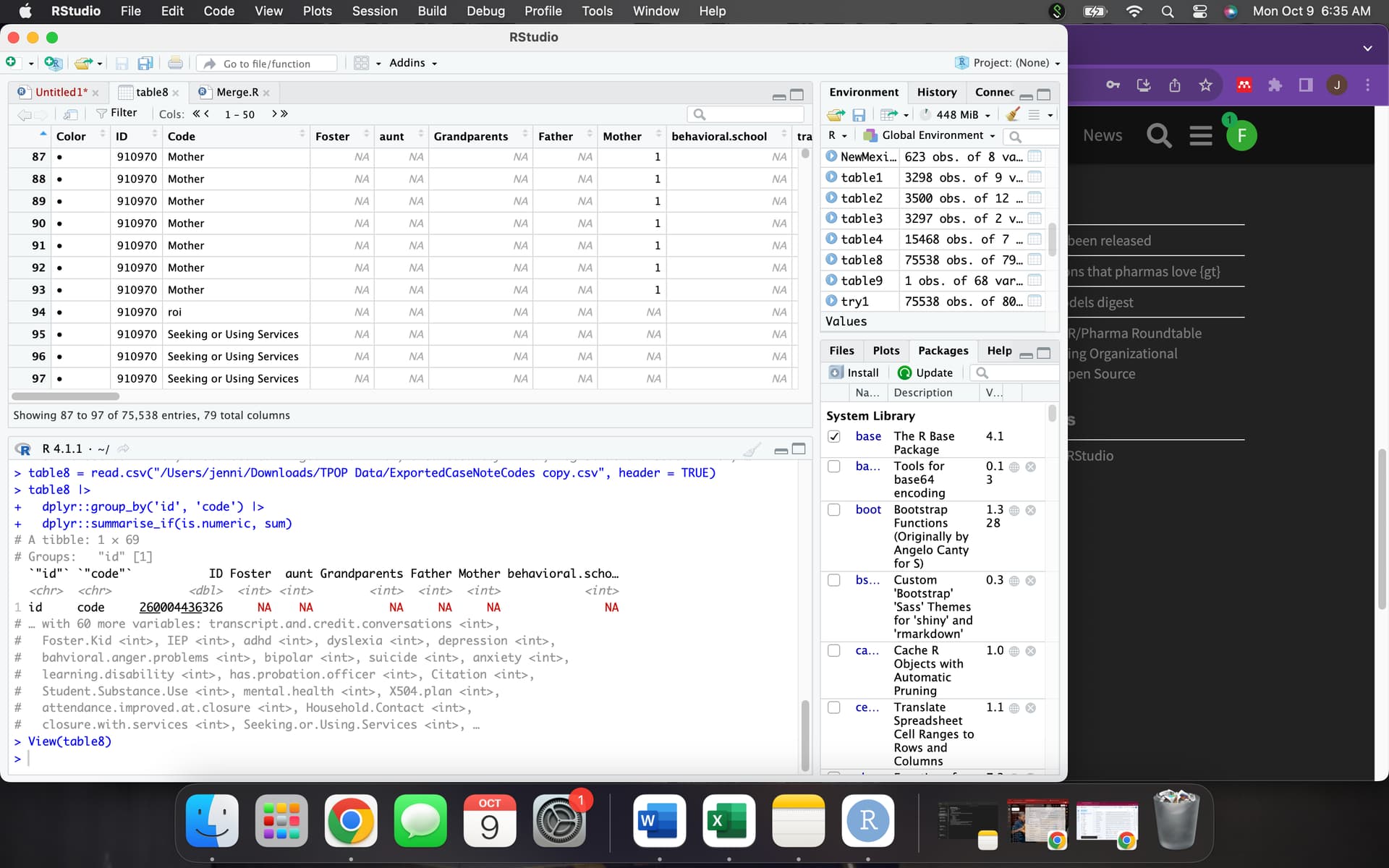
Thank you for catching that mistake! I fixed the capitols in the variable codes. It is still not doing what I need though.
Thank you for your help!
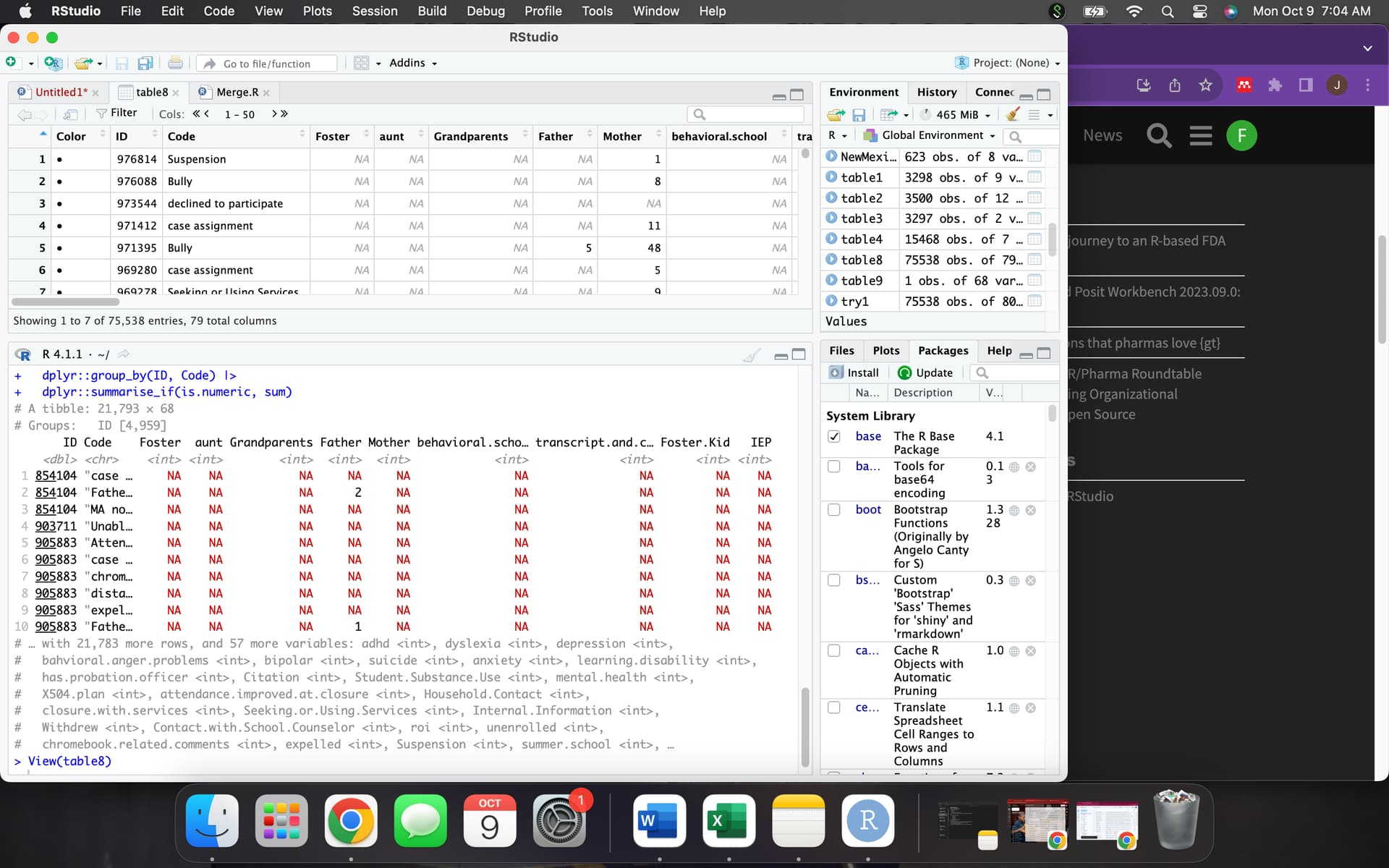
sum is functioning as designed, because what is the sum of 1 , 2 , NA.
it is NA, because you don't know , so you dont know...
if you want ignore the NA's you pass the na.rm=TRUE argument
either