Hi! I have a dataset that has several rows for each "id". I'd like to merge the rows so that all of the data for each unique "id" and "year" combination are contained in one row. Below is an example of my current data:
id<-c("A","A","A","A","A","A","B","B","B")
year<-c(1,1,1,2,2,2,1,1,1)
maytemp<-c(20,NA,NA,21,NA,NA,23,NA,NA)
juntemp<-c(NA,21,NA,NA,20,NA,NA,24,NA)
jultemp<-c(NA,NA,22,NA,NA,18,NA,NA,25)
df<-data.frame(id,year,maytemp,juntemp,jultemp)
View(df)
I am trying to get an output like this:
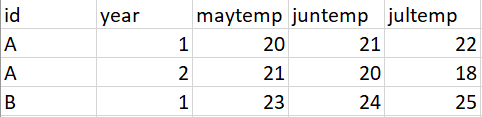
I'd appreciate any advice!