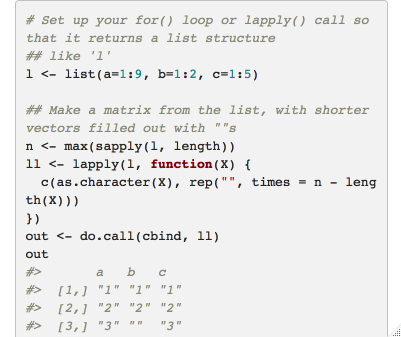
Dear all
I'm working on a tool to structure my bank transactions and create a comprehensive annual report. I have a list of about 600 transactions. I select the desired transactions for each journal entry with help of the grep function.
However, I want to check if each bank transaction is included in the overview:
for(transaction in all.transactions) {
x <- grep(transaction, dataset, perl = , value = F)
print(x)
}
Now R shows me the location of each used transaction as scanned by the grep function. However, now R shows only the location of the last iteration. I want that R merges x in this case for each iteration of the loop. How can I merge this? E.g. next loop:
result <- vector("numeric", 10)
for (i in length(result) ){
squared <- i^2
result[i] <- squared
}
result
Source: http://rfaqs.com/category/r-control-structure/for-loop-in-r
Hope that my issue is clear now. Thanks in advance.