Hi guys,
I´m experiencing an issue in my job trying to run a Random Forest Model.
My data is around 2.0M rows by around 90 columns after running the recipe.
The process is highly imbalanced, so I need to run a downsample and an upsample using CV. Downsample works great because It reduces to a tiny small dataset but after the upsample I would say I have around 2M rows by fold, 1.5M in analysis, and 0.5M in assessment.
What I have noticed is everytime I run a new object the RAM memory is not returned back to the OS, and when I get to the point of running RF I have memory to start but not to finish, I mean, sometimes it says some cores couldn´t retrieve info because they died, or sometimes all of the process go to sleep and this can be run forever. The longer this thing ran was 3 and a half hours just to notice all the process were slept. But normally after 1 minute, all the processes go to sleep.
I recreated a small reproducible example. Of course In this case I have plenty of memory remaining but just wanted to show that Memory is not released.
library(mlbench)
library(tidyverse)
library(tidymodels)
#> Registered S3 method overwritten by 'xts':
#> method from
#> as.zoo.xts zoo
#> ── Attaching packages ────────────────────────────────────────────────────────────────────────────────────── tidymodels 0.0.3 ──
#> ✓ broom 0.5.3 ✓ recipes 0.1.8.9000
#> ✓ dials 0.0.4 ✓ rsample 0.0.5
#> ✓ infer 0.5.1 ✓ yardstick 0.0.4
#> ✓ parsnip 0.0.4.9000
#> ── Conflicts ───────────────────────────────────────────────────────────────────────────────────────── tidymodels_conflicts() ──
#> x scales::discard() masks purrr::discard()
#> x dplyr::filter() masks stats::filter()
#> x recipes::fixed() masks stringr::fixed()
#> x dplyr::lag() masks stats::lag()
#> x dials::margin() masks ggplot2::margin()
#> x yardstick::spec() masks readr::spec()
#> x recipes::step() masks stats::step()
#> x recipes::yj_trans() masks scales::yj_trans()
library(tictoc)
#Data used for the example only
data("Ionosphere")
#not all of these steps apply for this but I tried to replicate as much as I could from my real case
tic()
up_recipe <- recipe(Class ~ . , data = Ionosphere) %>%
step_nzv(all_predictors()) %>%
step_corr(all_numeric(), threshold = 0.7) %>%
step_YeoJohnson(all_numeric()) %>%
step_dummy(all_nominal(), -all_outcomes()) %>%
step_center(all_numeric()) %>%
step_scale(all_numeric()) %>%
step_spatialsign(all_numeric()) %>%
step_upsample(Class, over_ratio = 0.5)
toc()
#> 0.019 sec elapsed
set.seed(071092)
library(rsample)
data_CV <- vfold_cv(Ionosphere, v = 10, repeats = 1, strata = Class)
# Activating forked processes
library(furrr)
#> Loading required package: future
options(future.fork.enable = TRUE)
cl <- availableCores() - 1
plan(multicore, workers = cl)
# This recipes was stored in a different object, becuase initially i was using mutate to append the model
# and several recipes and the object was huge and I ran out of memory
tic()
recipes_up <- data_CV$splits %>%
future_map(prepper, recipe = up_recipe)
toc()
#> 0.457 sec elapsed
tic()
model <- future_map(
recipes_up,
~ rand_forest(mode = "classification", trees = 200, mtry = 10) %>%
set_engine("ranger", num.threads = 1) %>%
fit(Class ~ ., data = juice(.x, everything()))
)
toc()
#> 1.031 sec elapsed
Created on 2019-12-30 by the reprex package (v0.3.0)
I´m running a Centos 7 Machine with Rstudio Server, 24 cores and 234 GB of RAM.
Initially these are my machine stats:
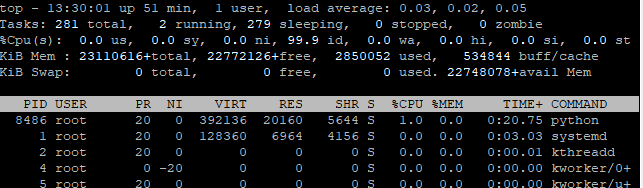
After running the recipes, you´ll notice that more RAM is set as used.
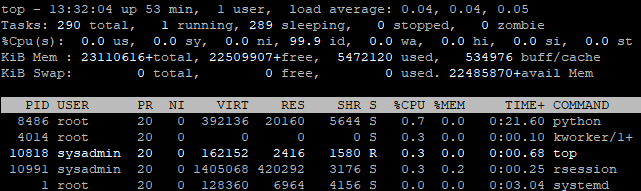
This screenshot is when running the RF model and you´ll see multiprocesses and
that RAM is higher.
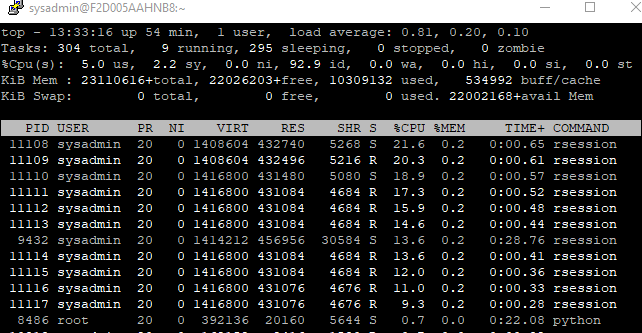
Could you guys help out understand why RAM is not being released and how can I manage it efficiently. Some people have told me I would need some docker + kubernetes solution, but sincerely I dont know about devOps and why I´d need those.
@Max and @davis I would really appreciate your help with this. If more details are needed I would be glad to provide more details.
Aditionally, sometimes I´m running instead of ranger H2o models, I´m still suing tidymodels infrastructure because I think recipes is way more powerful that built-in process in h2o. And sometimes i just can´t convert to h2o frame because of memory issues too.
Also, I will be testing {tune} as @Max suggested to see if this is an issue with the parallel backend or something else.
Thanks in advance,
Alfonso