Hello. This is my first post here, so hopefully I doing this correctly. I am a self-taught R learner and have been using Tidyverse for a few months.
I am having trouble applying a custom-made function onto a list that has a split. My data is very similar to the modified version of the gapminder data shown below.
Here is the data:
library(gapminder)
library(tidyverse)
df<- gapminder %>%
filter(country %in% c("Afghanistan", "Belgium", "Cameroon")) %>%
select(year, country, lifeExp, gdpPercap, pop) %>%
mutate(month = rep("01", nrow(df))) %>%
mutate(day = rep("01", nrow(df))) %>%
mutate(year = as.character(year)) %>%
unite_(col='date', c("year", "month", "day"), sep = "-") %>%
mutate(date = as.Date(date)) %>%
mutate(country = as.character(country))
df_split <- split(df, df$country)
I want to apply the following user-defined function onto the data at each level of split
PctChange <- function(x){
((x - lag(x,1)) / lag(x,1)) * 100
}
I was able to figure out how to apply the function on a single level of split
Afg_pct <- modify_if(df_split$Afghanistan, is.numeric, PctChange)
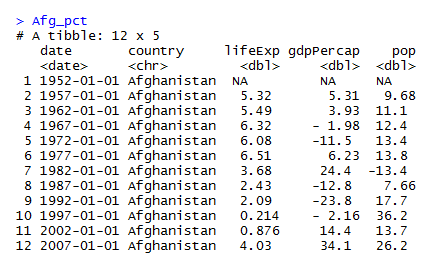
But I am really struggling to figure out how to apply this to each and every level of split in the data.
Due to the time-series nature of the data, it seems to me that this kind of a split/nested/grouped list should theoretically be useful. However, I am really stuck here.
Is there a simple solution to this that I am not thinking of?
Alternatively, should I look into reshaping the data so that the calculations are easier?
Any help would be hugely appreciated!! Thanks in advance.