kash
January 26, 2021, 12:07pm
1
Hi,
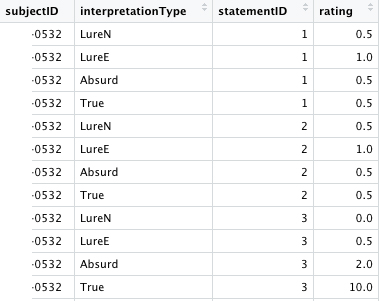
so I want to make some calculations on a data frame based on specific values and names of different columns:
So for instance for every unique "subjectID", I want to calculate the sum of the "rating" for "Absurd" with "statementID" 1 2 and 3, and the sum of "LureN" with "statementID" 3, and sum of "LureE" with "statementID" 3.
If it is not clear, here is what I want to do:
I have tried with this code so far:
sumratings <- aggregate(BADE_WEB$rating, by=list(BADE_WEB$subjectID, BADE_WEB$interpretationType, BADE_WEB$statementID), FUN=sum)
Which only gives separate values for all interpretationType and statementID.
All help is appreciated.
Hi,
Welcome to the RStudio community!
First of all, I'd like to point you towards our guide for creating a reprex so we can more easily use your data instead of sharing a screenshot. A reprex consists of the minimal code and data needed to recreate the issue/question you're having. You can find instructions how to build and share one here:
A minimal reproducible example consists of the following items:
A minimal dataset, necessary to reproduce the issue
The minimal runnable code necessary to reproduce the issue, which can be run
on the given dataset, and including the necessary information on the used packages.
Let's quickly go over each one of these with examples:
I recreated your dataset (some number are not the same in the rating) and used the dplyr package from the Tidyverse to create your results
library(dplyr)
#Get the data
myData = data.frame(
subjectID = "0532",
interpretationType = c("LureN", "LureE", "Absurd", "True"),
statementID = rep(1:3, 4),
rating = 0.5
)
myData
#> subjectID interpretationType statementID rating
#> 1 0532 LureN 1 0.5
#> 2 0532 LureE 2 0.5
#> 3 0532 Absurd 3 0.5
#> 4 0532 True 1 0.5
#> 5 0532 LureN 2 0.5
#> 6 0532 LureE 3 0.5
#> 7 0532 Absurd 1 0.5
#> 8 0532 True 2 0.5
#> 9 0532 LureN 3 0.5
#> 10 0532 LureE 1 0.5
#> 11 0532 Absurd 2 0.5
#> 12 0532 True 3 0.5
#Filter the data only to have the variables of interest
myData = myData %>%
filter(statementID == 3 | interpretationType == "Absurd",
interpretationType != "True")
myData
#> subjectID interpretationType statementID rating
#> 1 0532 Absurd 3 0.5
#> 2 0532 LureE 3 0.5
#> 3 0532 Absurd 1 0.5
#> 4 0532 LureN 3 0.5
#> 5 0532 Absurd 2 0.5
#Group the result by subjectID and calculate the sum
myData %>% group_by(subjectID) %>%
summarise(sumRatings = sum(rating), .groups = "drop")
#> # A tibble: 1 x 2
#> subjectID sumRatings
#> * <chr> <dbl>
#> 1 0532 2.5
Created on 2021-01-26 by the reprex package (v0.3.0)
If you don't know the Tidyverse yet, you can check out the basics of dplyr here. It's really handy once you get to know it!
Hope this helps,
kash
January 26, 2021, 2:21pm
3
Oh sorry, will do that in future posts.
Thanks a ton, definitely helped.
How would I do if I also wanted to subtract ratings for interpretationType True with statement ID 3?
Hi,
That would be possible with just a few changes:
library(dplyr)
#Get the data
myData = data.frame(
subjectID = "0532",
interpretationType = c("LureN", "LureE", "Absurd", "True"),
statementID = rep(1:3, 4),
rating = 0.5
)
myData
#> subjectID interpretationType statementID rating
#> 1 0532 LureN 1 0.5
#> 2 0532 LureE 2 0.5
#> 3 0532 Absurd 3 0.5
#> 4 0532 True 1 0.5
#> 5 0532 LureN 2 0.5
#> 6 0532 LureE 3 0.5
#> 7 0532 Absurd 1 0.5
#> 8 0532 True 2 0.5
#> 9 0532 LureN 3 0.5
#> 10 0532 LureE 1 0.5
#> 11 0532 Absurd 2 0.5
#> 12 0532 True 3 0.5
#Filter the data only to have the variables of interest
myData = myData %>%
filter(statementID == 3 | interpretationType == "Absurd")
myData
#> subjectID interpretationType statementID rating
#> 1 0532 Absurd 3 0.5
#> 2 0532 LureE 3 0.5
#> 3 0532 Absurd 1 0.5
#> 4 0532 LureN 3 0.5
#> 5 0532 Absurd 2 0.5
#> 6 0532 True 3 0.5
#Group the result by subjectID and calculate the sum
myData %>% group_by(subjectID) %>%
summarise(
sumRatings = sum(rating[interpretationType != "True"]) -
sum(rating[interpretationType == "True"]),
.groups = "drop")
#> # A tibble: 1 x 2
#> subjectID sumRatings
#> * <chr> <dbl>
#> 1 0532 2
Created on 2021-01-26 by the reprex package (v0.3.0)
PJ
kash
January 27, 2021, 12:37pm
5
Thanks a ton for taking your time! This helped a lot.
/K
1 Like
system
February 3, 2021, 12:37pm
6
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.