Hello
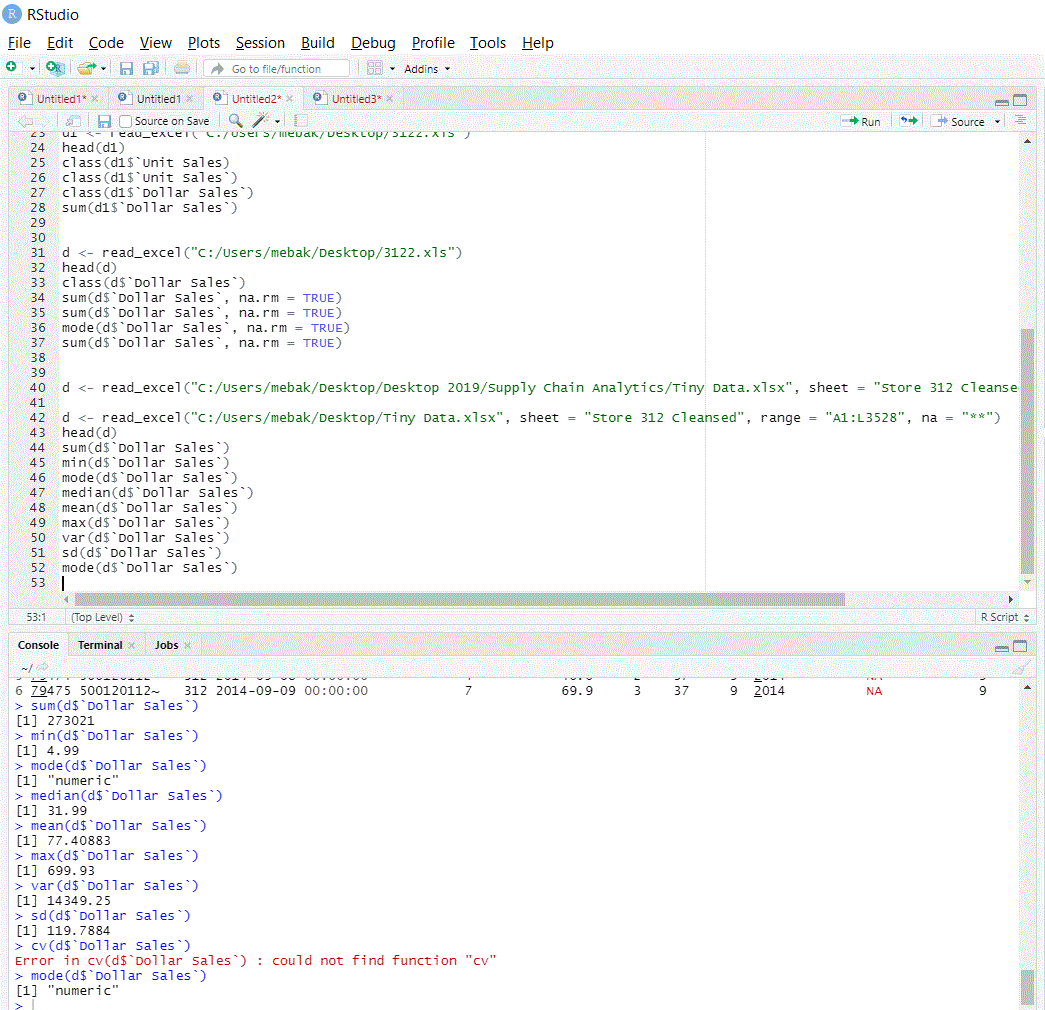
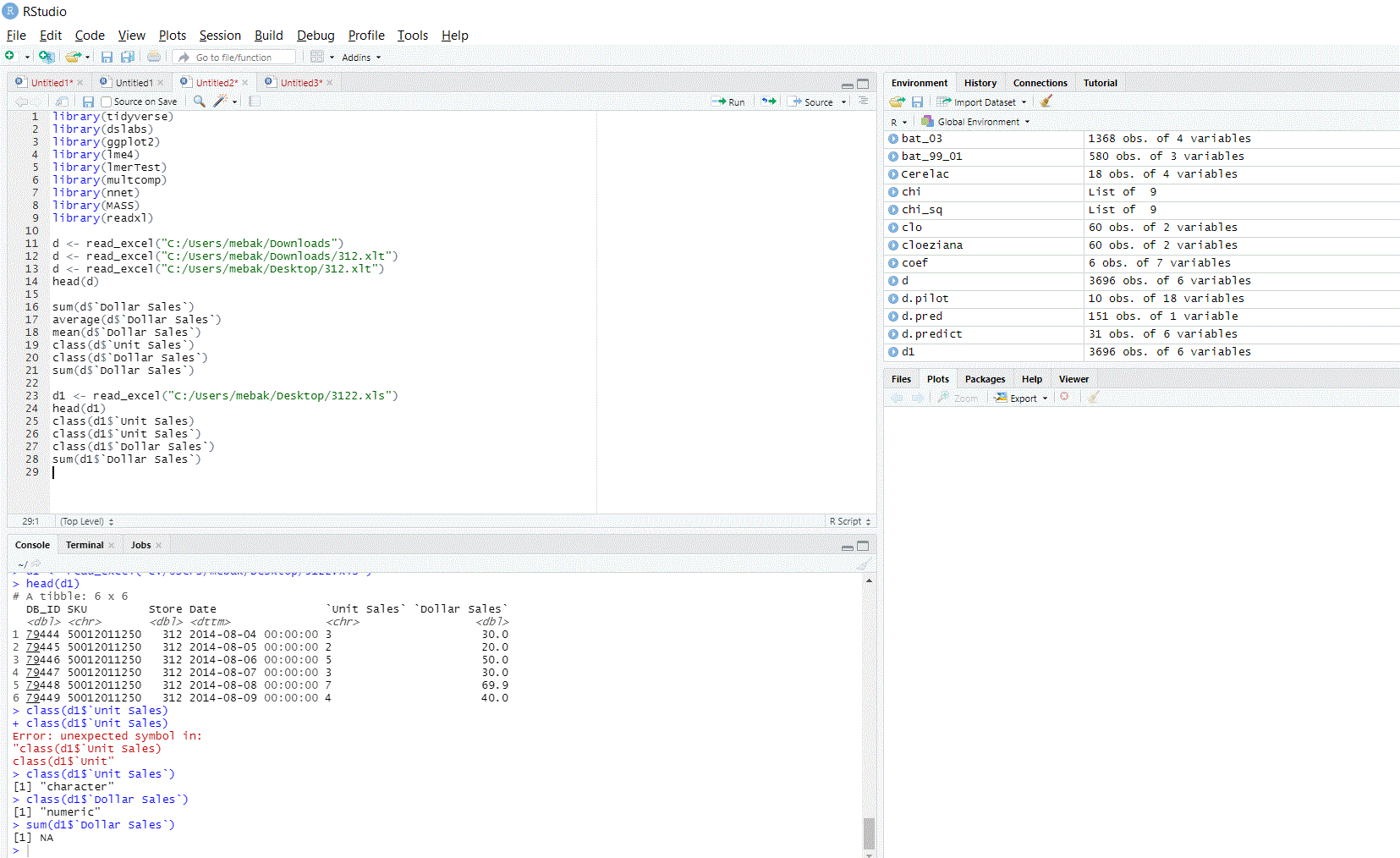
I am struggling to do a very basic kind of analysis to an excel sheet uploaded to R
I am trying to make a sum to the values of a numeric column and I usually get the same result, NA
File type: I uploaded two excel files: 1) Microsoft Excel 97-2003 Worksheet (.xls), 2) and the other is Microsoft Excel Template (.xlt)
I uploaded both files using
the following commands 1) library (readxl) 2) d <- read_excel ("----"), then 3) head (d) to check for the column heads. Both files were uploaded successfully.
Class of data: the column I am analyzing is titled "Dollar Sales" and I checked for the column type, using "Class" function and the answer is "numeric"
I am really wandering how and why I cannot make analysis , very basic summation equation to a numeric column?
Snap
shot is attached.