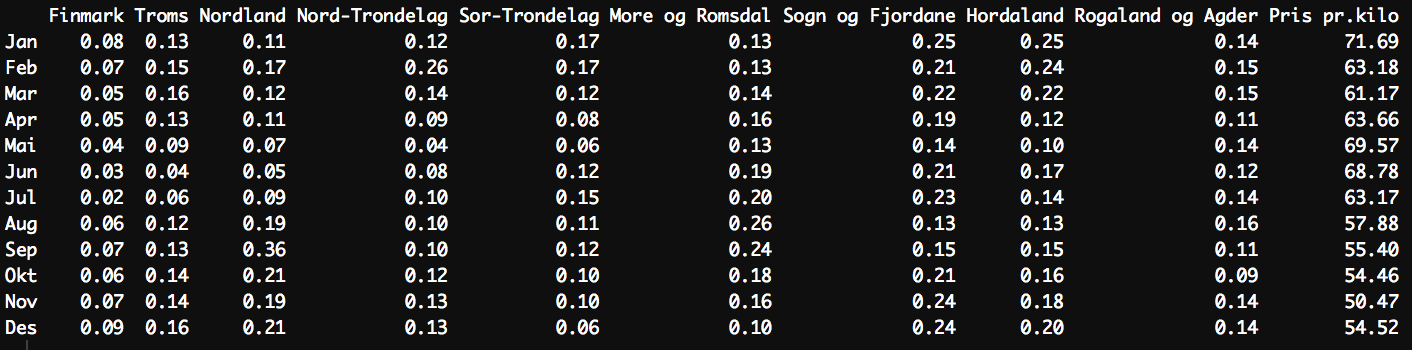
I have this matrix and following code:
# Remove NA-observations from dataset "lus" and removing row "totalsum"
lus2 <- na.omit(lus)
lus3 <- lus2[-c(10),]
# The problem now is that "laksepris" has months in the columns, while "lus" has months in the rows
laksepris2 <- laksepris %>%
spread (Month, Pris)
test <- rbind(setDT(lus3), setDT(laksepris2), fill=TRUE)
test[10,1] <- "Pris pr.kilo"
test_round <- test %>%
mutate_if(is.numeric, round, digits = 2)
#-------------------------------------------
rearranget_lus <- as.data.frame(t(test_round))
rearranget_lus
# Removing first row, and renaming the columns:
lus_1 <- rearranget_lus[-c(1),]
names (lus_1) [1] <- "Finmark"
names (lus_1) [2] <- "Troms"
names (lus_1) [3] <- "Nordland"
names (lus_1) [4] <- "Nord-Trondelag"
names (lus_1) [5] <- "Sor-Trondelag"
names (lus_1) [6] <- "More og Romsdal"
names (lus_1) [7] <- "Sogn og Fjordane"
names (lus_1) [8] <- "Hordaland"
names (lus_1) [9] <- "Rogaland og Agder"
names (lus_1) [10] <- "Pris pr.kilo"
I just started using R, and I am therefore wondering how I can run a correlation between the values in "pris pr.kilo" against the values in column "Finmark". Following I would also like to loop this, so that the loop runs the correlation between "pris.pr.kilo" and all the other columns as well.
Does anyone have a suggestion to how this is done?
Since I don't have access to your data, I'll create a synthetic data set.
library(tidyverse)
df <- data_frame(A = 1:12,
B = rev(A),
C = 2 * A,
D = 2 * B,
Y = 1:12)
> df
# A tibble: 12 x 5
A B C D Y
<int> <int> <dbl> <dbl> <int>
1 1 12 2 24 1
2 2 11 4 22 2
3 3 10 6 20 3
4 4 9 8 18 4
5 5 8 10 16 5
6 6 7 12 14 6
7 7 6 14 12 7
8 8 5 16 10 8
9 9 4 18 8 9
10 10 3 20 6 10
11 11 2 22 4 11
12 12 1 24 2 12
cor(A,Y) and cor(C,Y) should be 1. cor(B,Y) and cor(D,Y) should be -1.
I would break the dataframe into two pieces:
- the portion you want to loop over (X)
- and the portion that should stay constant (Y)
X <- select(df, -Y)
Y <- select(df, Y)
Now I can use map_df from the purrr package to feed each column of X to cor while setting the y parameter to Y. The output will be a dataframe.
library(purrr)
result <- map_df(X, cor, y = Y)
> result
# A tibble: 1 x 4
A B C D
<dbl> <dbl> <dbl> <dbl>
1 1 -1 1 -1
2 Likes
You can also do this with the corrr package. Using the dataset given by @Galangjs it would look like this:
library(tidyverse)
library(corrr)
df <- data_frame(A = 1:12,
B = rev(A),
C = 2 * A,
D = 2 * B,
Y = 1:12)
#default output of correlate function
corrr_result <- correlate(df)
#>
#> Correlation method: 'pearson'
#> Missing treated using: 'pairwise.complete.obs'
corrr_result
#> # A tibble: 5 x 6
#> rowname A B C D Y
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 A NA -1 1 -1 1
#> 2 B -1 NA -1 1 -1
#> 3 C 1 -1 NA -1 1
#> 4 D -1 1 -1 NA -1
#> 5 Y 1 -1 1 -1 NA
# look only at the desired comparison
corrr_result %>%
filter(rowname == "Y") %>%
select(-Y)
#> # A tibble: 1 x 5
#> rowname A B C D
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 Y 1 -1 1 -1
Created on 2018-08-29 by the reprex package (v0.2.0).
3 Likes