I need your help. So I am working on data analysis in R. N=105. I have the following dependent variables to analyse: Cost, knowledge, market, regulation, data availability and trust barriers for artificial intelligence/machine learning applications. These barriers could be indicated in a questionnaire on a scale of 1-5. I will binary code the barriers whenever they were ticked as a very important barrier (5) (suggested in the literature). Explanatory variables are: Extent of AI/ML applications in the company (could also be specified from 1-5) and I have saved these as dummy variables, i.e. with Unimportant, Little, Average, Important, Very important. I summarised the categories Important and Very important in ML_High, as there were very few mentions. Then there is the LN of the number of employees in the UN, LN of the percentage of university graduates and LN of the percentage of R&D investments. For each dependent variable, I perform a logistic regression with the same explanatory variables. This is my R code (where the dependent variable changes in each case): glm(Cost.B ~ Few + Average + ML_High + LN_Employees + LN_University_Leavers+ LN_FEI, family=binomial(link="logit"), data = data.sub). The problem is that in four out of six regressions this works and significant values are obtained, in two regressions the estimate and the Std.error for ML_High is miles too high. What could be the reason for this? What would be solutions?
One possibility is that glm has not converged to the proper value. (Possible, although not terribly likely.)
Unlike a least squares regression, estimating a logit involves a search procedure and sometimes the search stops in the wrong place. You can try starting at what you think are reasonable values by specifying the start argument to glm.
in two regressions the estimate and the Std.error for ML_High is miles too high
how are you arriving at this judgement ?
Sometimes we are correct in our understandings and contextual information, and can identify a poor model as a result.
sometimes we are incorrect in our understandings and this can result in us being suprised that we are wrong in our expectectations.

Try doing the same estimate only using lm instead of glm. This is called a linear probability model. Then see what the t-statistic looks like on ML_Hoch. (The coefficients will be completely different from what you see here. Don't worry about that.)
If the t-statistic is still small, then the message is that the effect of ML_Hoch isn't well identified. If the t-stat is large, then something is indeed going wrong in the logit.
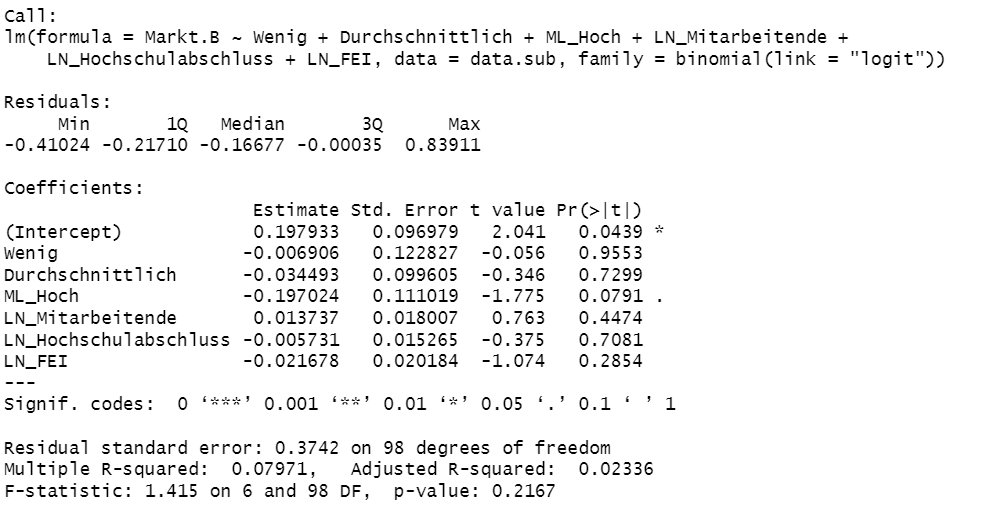
By "isn't well identified" I meant that the confidence interval is huge. Note that's not what happens with the least squares estimate (by the way, family doesn't mean anything in lm). ML_Hoch has a relatively tight confidence interval.
I would go back to the logit and try some different starting values for the parameters. But note that in your original logit that none of the parameters are statistically significant at the usual level and that's also true for least squares. It's quite possible that these variables just don't explain Markt.B.
I have six dependent variables representing barriers for AI/ML applications, and I'm using the glm function to perform logistic regression with various explanatory variables, including the extent of AI/ML applications in the company, LN of the number of employees, and other factors. Strangely, in four out of six regressions, the results are as expected and significant.
This topic was automatically closed 42 days after the last reply. New replies are no longer allowed.
If you have a query related to it or one of the replies, start a new topic and refer back with a link.