Hi,
I have a folder that contains csv's in it, each file has around 3K rows/observations and 600 variables.
I've seen various topics about the subject and came up with my own "solution".
Create auxiliary function that reads csv, adds file name so I can later extract info from the filename which contains the year for each csv.
library(tidyverse)
library(fs)
### List CSV files in directory
csv_files <- fs::dir_ls("ACS_DP02_data")
# Aux function call to append file names:
read_plus <- function(flnm) {
read_csv(flnm ) %>%
mutate(filename = flnm)
}
# Create df from csv files
my_df1 <- csv_files %>% map_df(read_plus)
Initially it seemed to work, as seen below:
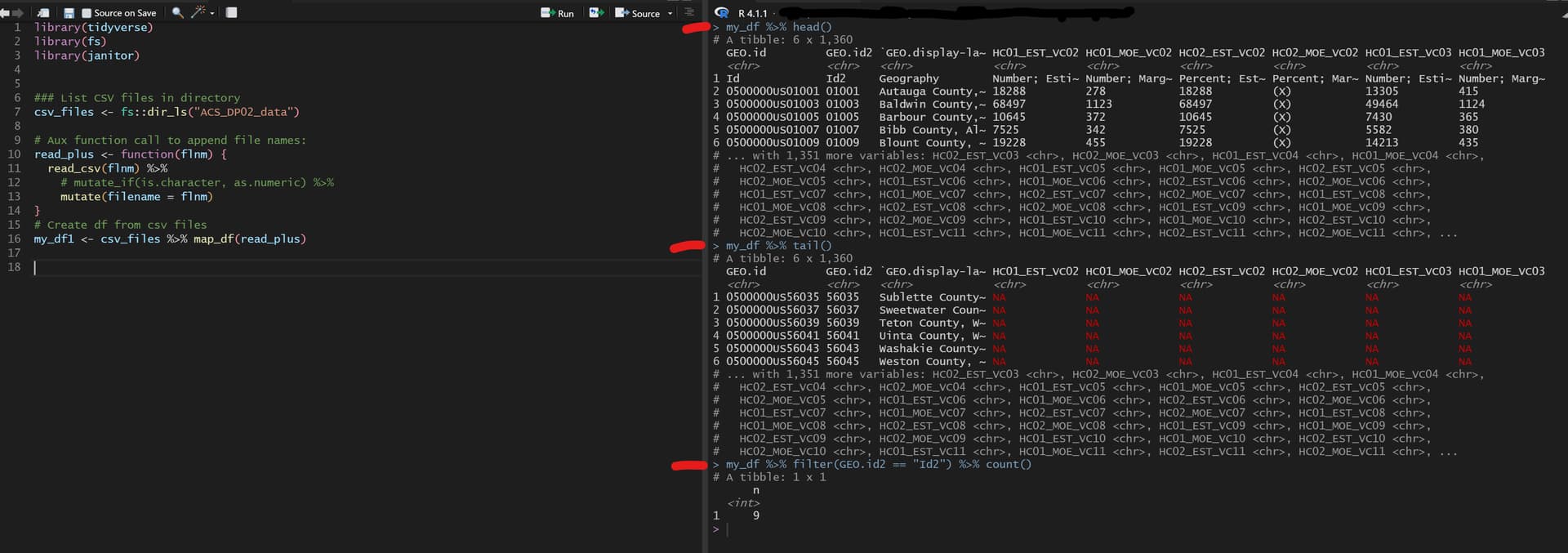
It looked right but then I noticed on observation 1, the row name... looked at the tail (theoretically last csv file in folder) checked file (csv) and tail (df) and it did not match. I also noticed that Id2 came up 9 times, indicating that the tables were attached after each other into a single df but the observations names were in there as well.
So I played around loading single files and noticed that I should skip 1st row. The data was imported correctly on individual files. Adding the skip = 1 to read_csv(), when attempting the 6th file I got the below error, basically not combining char with dbl .
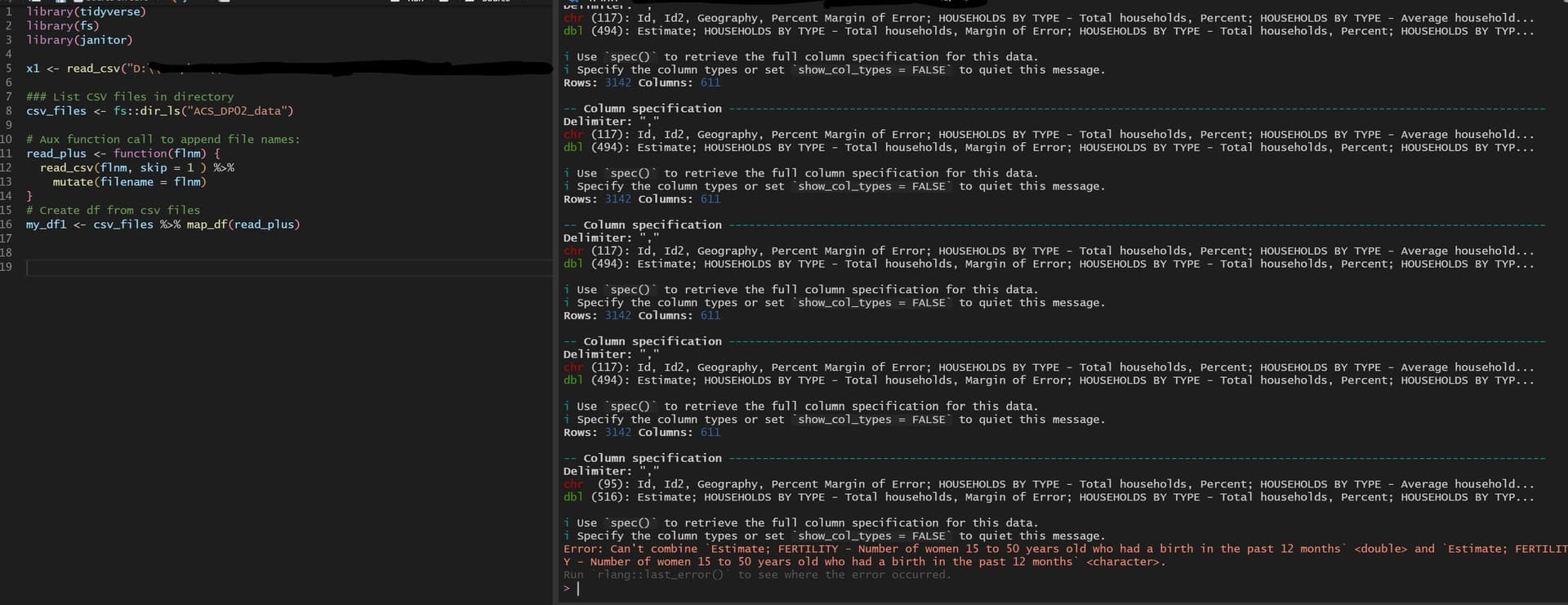
Single file loading using read_csv() and skip = 1 would load data correctly, as seen below:
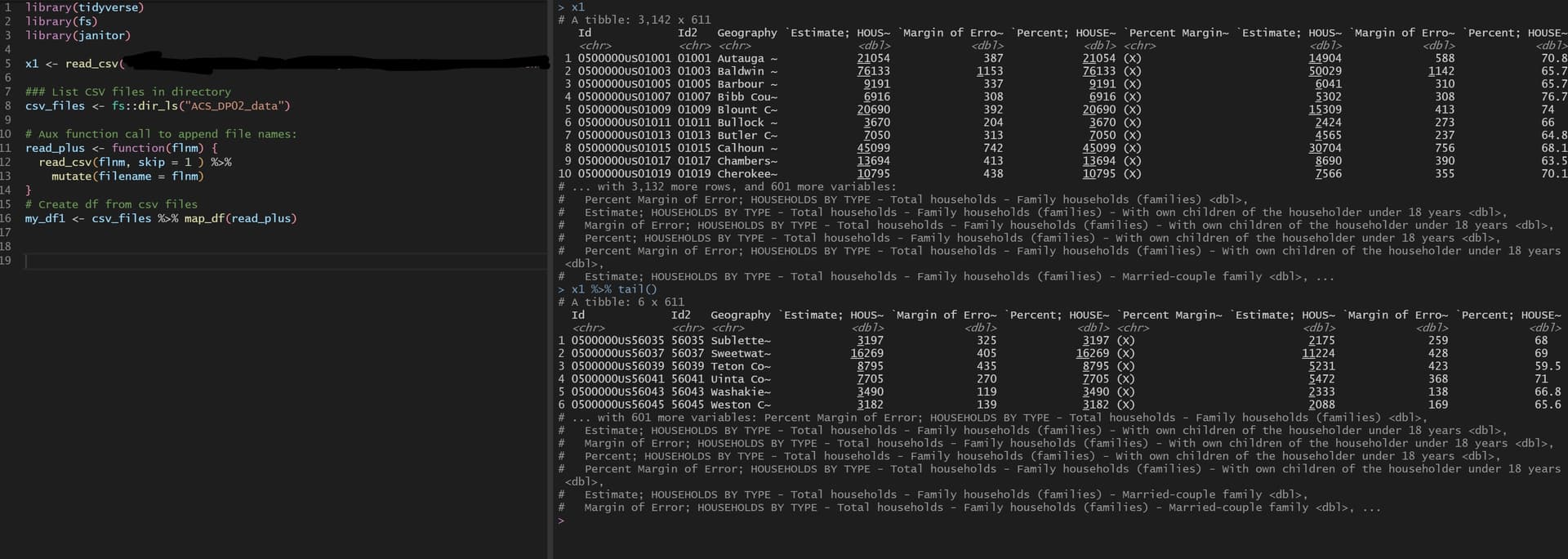
I therefore concluded I had to check if the variables were character and convert them to numeric, which lead me to the below code:
library(tidyverse)
library(fs)
### List CSV files in directory
csv_files <- fs::dir_ls("ACS_DP02_data")
# Aux function call to append file names:
read_plus <- function(flnm) {
read_csv(flnm) %>%
mutate_if(is.character, as.numeric) %>%
mutate(filename = flnm)
}
# Create df from csv files
my_df1 <- csv_files %>% map_df(read_plus)
It seemed to have worked but when I checked the data everything that was character was now NA, like below:
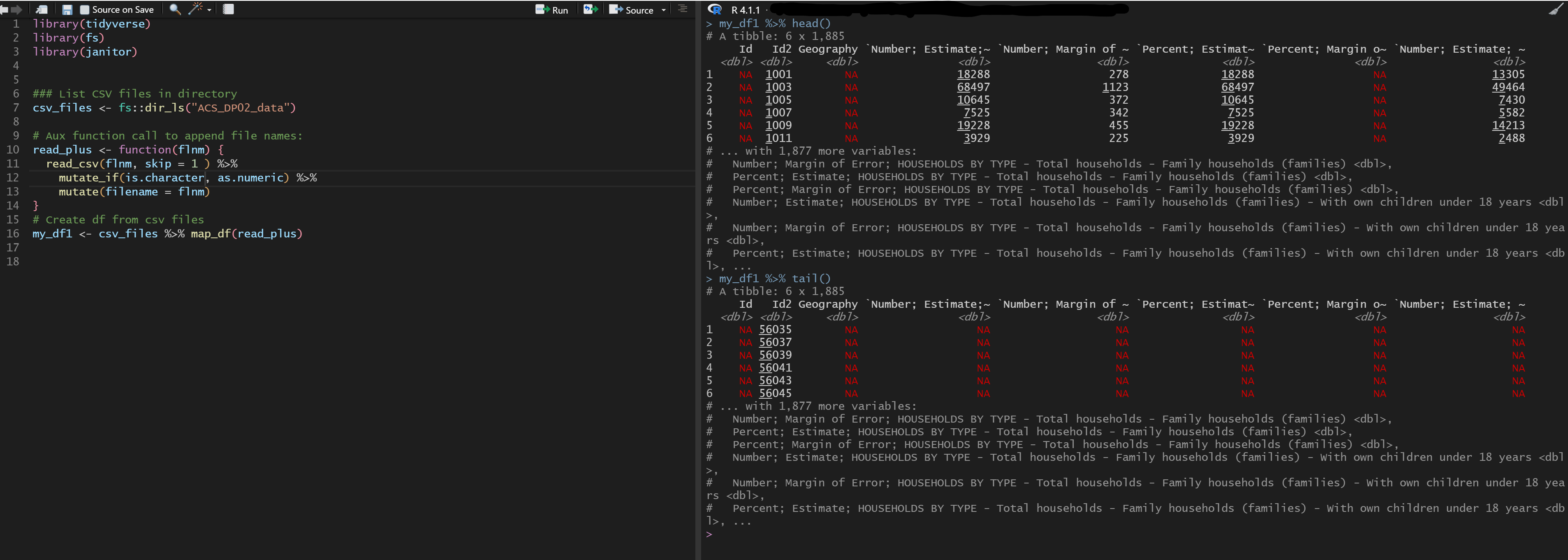
Could anyone shine a light what's going on? I suspect my mutate_all() is not doing what I think it is... I've been troubleshooting this for quite some time now and I'm frustrated.
Well thank you for your time beforehand and patience.