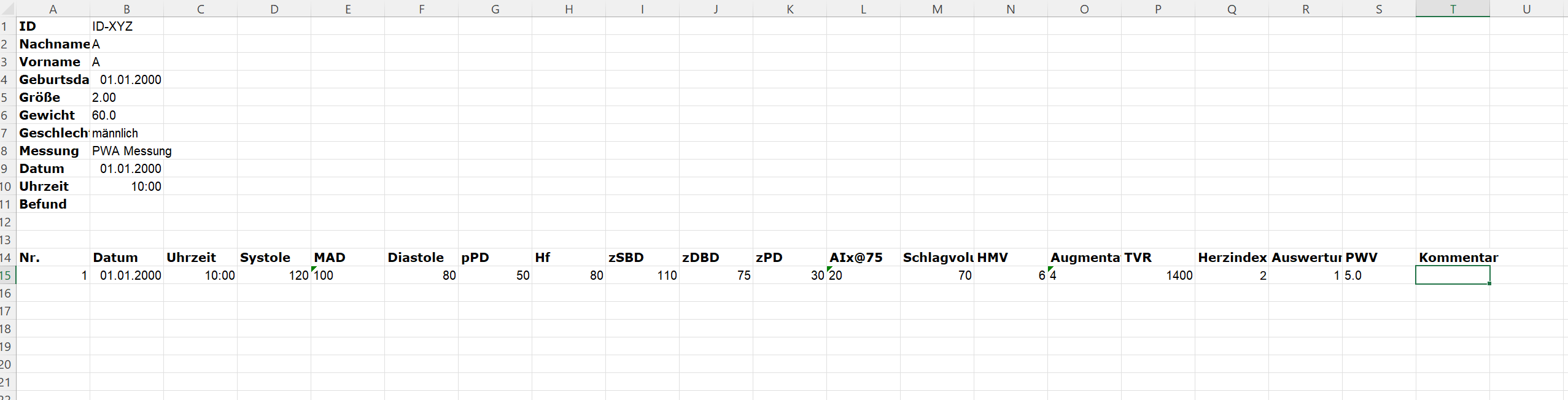
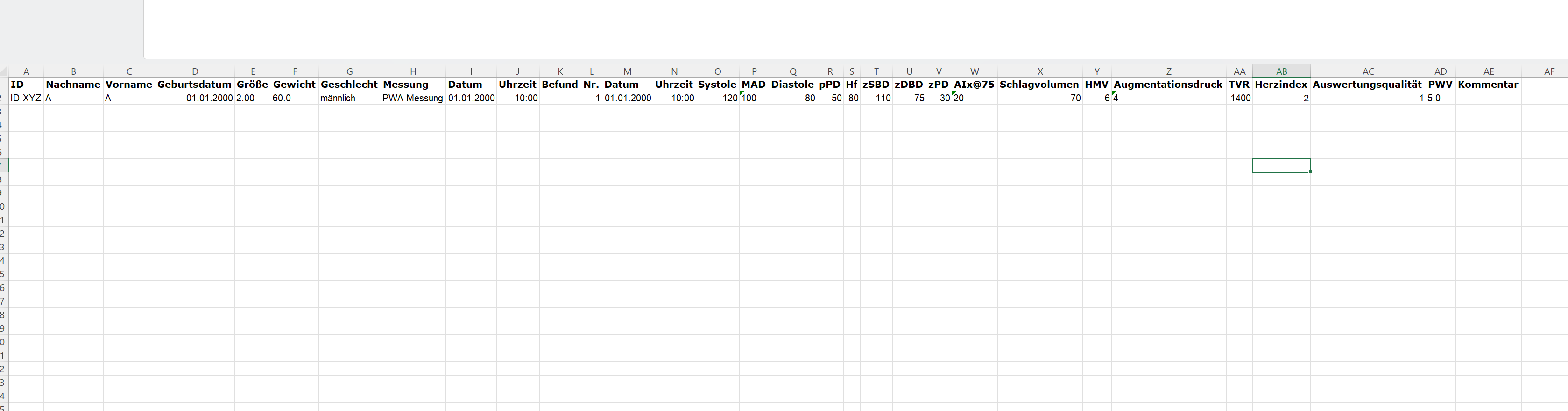
I am trying to write a code for R that helps me load about 2000 xls files from an folder and makes one large table out of it.
The problem that I am facing is the way the files are built when we download them from the software.
I already managed to import the files, but the table only shows me the names of the files, type of file, ect., but not the content of the files. And since I am very much a beginner at programming, I don't know where I should start fixing things.
Hi, welcome to the forum.
The best idea would be to upload that Excel file to a file sharing service such as Dropbox or Mediafire and post a link to it here. Or, perhaps even better to zip 3 or 4 files together and upload the zip file.
It is weird that you are getting "the names of the files, type of file, ect." but nothing else.
Could you post the code that you are using here? Copy the code and paste it here between
```
```
And remember to say a pious little curse every night on spreadsheet designers who produce such monstrosities.
@jrkrideau is right that uploading some files would be very helpful for providing specific guidance. For a general answer, I would read the data in two steps. Read rows 1:11 and columns 1:2 in one step and rows 14:15 and columns 1:20 in a second step. The read.xlsx() function in the openxlsx package allows you to pick rows and column to read and other packages probably have similar options. You can then use the pivot_wider() function from the tidyr package to pivot the first table to be a single row of 11 columns. Finally, you can column bind the pivoted table and the second table you read into a single table of one row with all the information.
Thank you verry much for the quick responses
i dont know why but the R skipt I worked on till yesterday cant be opend anymore.
But even though I think I used the same code as before the data dosn't open at all anymore. It only shows me "# A tibble: 0 × 0" at the end of the console.
I can't upload the original data sets, since they contain Informations on patients and students we tested on but I made three examples and a final form example and uploadded it to this folder: Dropbox
I thought I found my mistake that i forgot to move the data into my R Studio project folder but moving it to the specific folder did not help. It still can not open the file. Could it be because it is a xls file and not a more modern xlsx file?
Error:
filepath: C:\Users\paula\OneDrive\Desktop\Mobil-O-Graph\data\Schulmessungen\Messung Sandesneben\2024-05-30_09-56_22_ID-2024-0000000005_PWA.xls
libxls error: Unable to open file
Or is there an easier way to do it in Excel and then transfer it to R Studio as a complete table?
How do i select just specific rows and move them. I only ever used pivot_longer and pivot wider to switch whole tables but i never used it it on specific parts and I dont remember this part in the online leaning courses I did
Thank you verry much. At first it didnt work due to the old xls formate but after I converted a few files to csv and adapted the code it gave me a complete table.
With the CSV files the first part also works. But I now have to figure out how to connect the two parts to get one complete table
My code so far that I will hopefully improve tomorrow
This part does give me a overview list of all the files and one large table of all the files without them being in the right format. I have 21 files of the old format behind each other.
full_data2 <- cbind(pdt2, dat2)
It does work. I copied yours and doubled it to test it out with two different files and how to combine them. So I have one with final_data1 and one with final_data2 and I adapted all the data names from before. But the final_data1 copies file name contains sensitive data and with the final_data I tried to combine final_data1 and 2.
But I am to tired now and will look into it after work tomorrow.
The problem I am facing now is that some measurements have 29 columns while most have 20 columns, and they are arranged differently, so I can't just join them together.
After that, I think I only have to work on combining the correct measurements with the correct person file.
Is there any way to easily distinguish which are which? If so it should be fairly easy to read them into separate tibbles, re-arrange the column order of the "29-column" file to conform to the 20 column one and then "rbind" them together.
It might make sense to have two separate folders.
You will just end up with those 9 columns column having a lot of "NA"s but that is not a problem.
I will try that tomorrow. The problem with splitting them in 20 and 29 collums is merging them back together and bringing them into the right order. The IDs are only in the person's part and we need the IDs to connect the measurements to the other test we performed
I think we are visualizing this in different ways.
As I visualize it you simply split all the .xls (or .csv) files into two groups. Say two folders. One has all the 20-columns and one has all the 29-columns. We process them independently, but . Sort the 29-columns output into the same order as the 20-column order.
rbind the two data.frames together. This should not affect the ID variable at all. We never touch the 9 columns independently.
Actually I will have think about it a bit more but unless I am seriously misunderstanding the data structure it is a "simple" approach.
If you are sorting 2000 files by hand(!!!) just toss the 20-column ones into one folder and the 29-column ones into another folder.
Conceptually, you are doing the same thing to each file. Then at the end you have two data.frames or tibbles. You rearrange one to get the same column order as in the other but with the nine extra columns stuck on in one and do an rbind.
First set of files
ID, AA, BB, CC
Second set of files
XX, ID, AA, ZZ, BB, KK, CC
Reorder Second set of files
ID, AA, BB, CC, KK, XX, ZZ
You can then do an rbind. The files from the first set will have NA's in the KK, XX, ZZ columns but that is no problem
It actually wasn't that hard to seperate the 29 colum files by hand. The 29 colum files had a slight different in the name. With the 29 colum files everything works after I used a python programm to transfer them to csv. Only now, using all of the 20 colum files I found several 28 colum files that have no difference in their name and there are a lot more of them.
I don't know. I've been trying to think of an obvious way and I cannot see one.
I'd suggest starting a new thread on exactly this problem. I think it should be possible but I don't have enough knowledge of .xls file structure to know if it can be done there.
It may be possible to load all the files into one R data.frame or tibble, with the varying numbers of columns and then filter out the three different column-length sets into different tibbles, clean them up and rebuild the original tibble but I have no idea how at the moment.
I was just thinking of creating a couple of example files with 29 columns and seeing if I could come up with anything.
I'd really suggest a new post that some real munging experts might find a challenge. This tread is old enough that a lot of people will ot be following it.