Hello! I'm a data science student and I'm trying to tidy some data I got from an xlsx file. I was able to import the file to rstudio but now, I have no idea on how to tidy the data. I'd like to keep 2 columns: 1 for the CVEs and another for the hosts. I've tried many different tutorials from the web to no avail. I attached a picture of where I'm stuck. Thanks for the help.
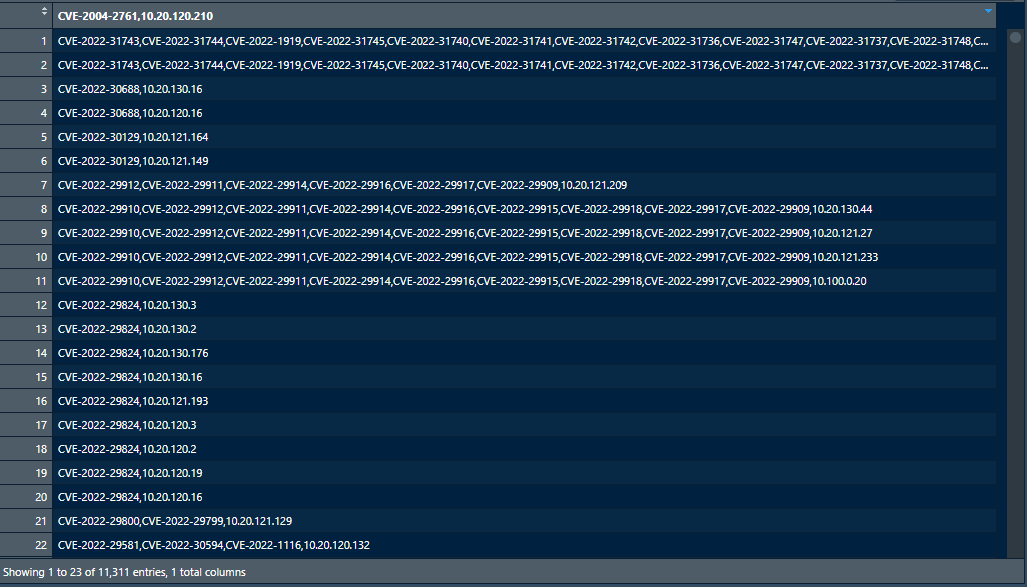
Can you please share a small part of the data set in a copy-paste friendly format?
In case you don't know how to do it, there are many options, which include:
Like this:
"CVE-2020-1529,CVE-2020-1337,CVE-2020-1513,CVE-2020-1557,CVE-2020-1579,CVE-2020-1558,CVE-2020-1339,CVE-2020-1515,CVE-2020-1537,CVE-2020-1516,CVE-2020-1538,CVE-2020-1377,CVE-2020-1476,CVE-2020-1378,CVE-2020-1477,CVE-2020-1554,CVE-2020-1379,CVE-2020-1478,CVE-2020-1577,CVE-2020-1534,CVE-2020-1472,CVE-2020-1473,CVE-2020-1474,CVE-2020-1475,CVE-2020-1530,CVE-2020-1552,CVE-2020-1470,CVE-2020-1570,CVE-2020-1517,CVE-2020-1518,CVE-2020-1519,CVE-2020-1520,CVE-2020-1564,CVE-2020-1587,CVE-2020-1467,CVE-2020-1489,CVE-2020-1567,CVE-2020-1484,CVE-2020-1485,CVE-2020-1562,CVE-2020-1584,CVE-2020-1046,CVE-2020-1464,CVE-2020-1486,CVE-2020-1380,CVE-2020-1383,192.168.100.107",
",192.168.100.107", "CVE-2020-1091,CVE-2020-0718,CVE-2020-0912,CVE-2020-0836,CVE-2020-1508,CVE-2020-0838,CVE-2020-0921,CVE-2020-1559,CVE-2020-0922,CVE-2020-0761,CVE-2020-1256,CVE-2020-1598,CVE-2020-0664,CVE-2020-1038,CVE-2020-1115,CVE-2020-1039,CVE-2020-1252,CVE-2020-1593,CVE-2020-1012,CVE-2020-0782,CVE-2020-1013,CVE-2020-1376,CVE-2020-1596,CVE-2020-1491,CVE-2020-1030,CVE-2020-1052,CVE-2020-1074,CVE-2020-1250,CVE-2020-1031,CVE-2020-1097,CVE-2020-0648,CVE-2020-1319,CVE-2020-1228,CVE-2020-0856,CVE-2020-0878,CVE-2020-0911,CVE-2020-1245,CVE-2020-1589,CVE-2020-0790,CVE-2020-1285,CVE-2020-1083,192.168.100.107",
"CVE-2021-43222,CVE-2021-43233,CVE-2021-43893,CVE-2021-43223,CVE-2021-43234,CVE-2021-43245,CVE-2021-43883,CVE-2021-43230,CVE-2021-43217,CVE-2021-43207,CVE-2021-43229,CVE-2021-41333,CVE-2021-40441,CVE-2021-43224,CVE-2021-43236,CVE-2021-43215,CVE-2021-43226,CVE-2021-43216,CVE-2021-43238,192.168.100.107",
"CVE-2021-31186,CVE-2021-26419,CVE-2021-31188,CVE-2021-31194,CVE-2021-31182,CVE-2021-31193,CVE-2020-24587,CVE-2020-24588,CVE-2021-31184,CVE-2021-28476,CVE-2021-28455,CVE-2020-26144,192.168.100.107",
"CVE-2021-31958,CVE-2021-31968,CVE-2021-31959,CVE-2021-31954,CVE-2021-31953,CVE-2021-31956,CVE-2021-31201,CVE-2021-31971,CVE-2021-33742,CVE-2021-31962,CVE-2021-31973,CVE-2021-31199,CVE-2021-1675,CVE-2021-26414,192.168.100.107"
)), class = c("tbl_df", "tbl", "data.frame"), row.names = c(NA,
-11311L))
Almost, you haven't posted the complete dput output, it is missing the initial part, please check again and post the complete output.
To post the data use
dput(data-name), then copy and paste the output.
It is gigantic! 11K lines. Can I use a pastebin website?
A few lines like in your screenshot would be enough
dput(head(data-name, 20))
Alternatively you can share a link to the raw xlsx file. Maybe this would be a better option since it seems you haven't correctly imported the data on the first place (one record is on the column header)
The xlsx is in fact a csv I transformed. Unfortunately, I can't share the document, it's a report from a client. I notice the record on the header, and yeah, I probably messed up a bit.
Then a few rows from the raw file opened as text would help us identify potential issues and maybe avoid the need for manually separating columns.
Since you are already showing about 20 records on the screenshot I don't think you would have further data security concerns if you share the same data as raw text.
Point taken. I'll do that tomorrow. The file is in my work laptop and today is a holiday here. Thanks for all the insights so far.
That is a screenshot, unless someone is willing to manually type it from the image, it is of no use.
You could simply copy and paste here a few lines directly from your csv file, that way we can simply paste it in a text editor and have a small sample of your raw csv file.
Here is a rough example of what we need as a csv file.
"","flag","country","x2021_live","x2020_population","area","density_km2","growth_rate","world_percent","rank"
"1",NA,"China","1,444,463,616","1,439,323,776","9,706,961 km²","149/km²","0.34%","18.34%",1
"2",NA,"India","1,394,095,436","1,380,004,385","3,287,590 km²","424/km²","0.97%","17.69%",2
"3",NA,"United States","333,014,395","331,002,651","9,372,610 km²","36/km²","0.58%","4.23%",3
"4",NA,"Indonesia","276,507,330","273,523,615","1,904,569 km²","145/km²","1.04%","3.51%",4
"5",NA,"Pakistan","225,419,269","220,892,340","881,912 km²","255/km²","1.95%","2.86%",5
"6",NA,"Brazil","214,066,360","212,559,417","8,515,767 km²","25/km²","0.67%","2.72%",6
"7",NA,"Nigeria","211,670,609","206,139,589","923,768 km²","229/km²","2.55%","2.68%",7
"8",NA,"Bangladesh","166,385,502","164,689,383","147,570 km²","1,127/km²","0.98%","2.11%",8
"9",NA,"Russia","145,910,977","145,934,462","17,098,242 km²","9/km²","-0.02%","1.85%",9
"10",NA,"Mexico","130,330,309","128,932,753","1,964,375 km²","66/km²","1.03%","1.65%",10
"11",NA,"Japan","126,029,236","126,476,461","377,930 km²","334/km²","-0.34%","1.60%",11
"12",NA,"Ethiopia","118,025,144","114,963,588","1,104,300 km²","107/km²","2.53%","1.50%",12
"13",NA,"Philippines","111,122,158","109,581,078","342,353 km²","324/km²","1.34%","1.41%",13
"14",NA,"Egypt","104,356,694","102,334,404","1,002,450 km²","104/km²","1.88%","1.32%",14
"15",NA,"Vietnam","98,211,145","97,338,579","331,212 km²","296/km²","0.85%","1.25%",15
It should be possible for someone to paste this into text editor and then read it into R.First: sorry for my being painfully dumb and slow.
Second: thank you very much for all the time and patience spent with me.
Third time is charm, right?
"CVE-2004-2761,10.20.120.210"
"CVE-2017-10081,CVE-2017-10078,CVE-2017-10111,CVE-2017-10114,CVE-2017-10135,CVE-2017-10053,CVE-2017-10074,CVE-2017-10096,CVE-2017-10110,CVE-2017-10176,CVE-2017-10198,CVE-2017-10116,CVE-2017-10115,CVE-2017-10118,CVE-2017-10117,CVE-2017-10193,CVE-2017-10090,CVE-2017-10101,CVE-2017-10145,CVE-2017-10067,CVE-2017-10089,CVE-2017-10243,CVE-2017-10125,CVE-2017-10102,CVE-2017-10086,CVE-2017-10121,CVE-2017-10087,CVE-2017-10109,CVE-2017-10108,CVE-2017-10105,CVE-2017-10104,CVE-2017-10107,10.20.120.210"
",10.20.120.233"
",10.20.120.233"
"CVE-2021-20233,CVE-2020-27779,CVE-2020-25632,CVE-2020-15707,CVE-2020-10713,CVE-2020-14308,CVE-2020-15706,CVE-2020-14309,CVE-2020-15705,CVE-2020-14310,CVE-2020-14311,CVE-2020-14372,CVE-2020-25647,CVE-2020-27749,CVE-2021-20225,CVE-2021-3418,10.20.121.134"
"CVE-2018-3620,CVE-2017-5753,CVE-2018-12127,CVE-2017-5754,CVE-2019-11135,CVE-2018-3639,CVE-2018-3615,CVE-2018-12126,CVE-2018-12130,CVE-2018-3646,CVE-2017-5715,10.20.120.12"
",10.70.120.252"
",10.70.120.252"
",10.70.120.252"
"CVE-2004-2761,10.81.120.251"
"CVE-2021-4189,CVE-2021-3737,10.20.153.40"
",10.20.120.47"
"CVE-2013-1862,CVE-2013-1896,10.20.121.14"
"CVE-2014-0118,CVE-2014-0231,CVE-2013-5704,CVE-2014-0226,10.20.121.14"
"CVE-2021-20233,CVE-2020-27779,CVE-2020-25632,CVE-2020-15707,CVE-2020-10713,CVE-2020-14308,CVE-2020-15706,CVE-2020-14309,CVE-2020-15705,CVE-2020-14310,CVE-2020-14311,CVE-2020-14372,CVE-2020-25647,CVE-2020-27749,CVE-2021-20225,CVE-2021-3418,10.20.121.169"
"CVE-2016-2183,10.20.121.14"
"CVE-2015-4000,10.20.121.14"
"CVE-2016-2183,10.70.120.233"
"CVE-2018-3620,CVE-2017-5753,CVE-2018-12127,CVE-2017-5754,CVE-2019-11135,CVE-2018-3639,CVE-2018-3615,CVE-2018-12126,CVE-2018-12130,CVE-2018-3646,CVE-2017-5715,10.81.120.251"
"CVE-2018-3620,CVE-2017-5753,CVE-2018-12127,CVE-2017-5754,CVE-2019-11135,CVE-2018-3639,CVE-2018-3615,CVE-2018-12126,CVE-2018-12130,CVE-2018-3646,CVE-2017-5715,10.70.120.233"
"CVE-2017-3099,CVE-2017-3100,CVE-2017-3080,10.20.120.12"
"CVE-2019-7090,10.20.120.12"
"CVE-2015-0008,10.20.120.21"
"CVE-2016-3550,CVE-2016-3485,CVE-2016-3552,CVE-2016-3498,CVE-2016-3503,CVE-2016-3587,CVE-2016-3598,CVE-2016-3500,CVE-2016-3511,CVE-2016-3610,CVE-2016-3458,CVE-2016-3606,CVE-2016-3508,10.20.120.210"
",10.20.120.233"
"CVE-2010-1130,CVE-2010-1129,CVE-2010-1128,10.20.121.14"
"CVE-2012-1823,10.20.121.14"
",10.81.120.59"
",10.20.121.90"
"CVE-2018-3620,CVE-2017-5753,CVE-2018-12127,CVE-2017-5754,CVE-2019-11135,CVE-2018-3639,CVE-2018-3615,CVE-2018-12126,CVE-2018-12130,CVE-2018-3646,CVE-2017-5715,10.20.120.60"
"CVE-2016-2183,10.20.120.210"
",10.20.120.233"
"CVE-2015-6161,10.20.120.251"
"CVE-2020-3757,10.20.120.12"
"CVE-2021-21997,10.20.120.21"
"CVE-2016-4111,CVE-2016-4112,CVE-2016-4113,CVE-2016-4114,CVE-2016-1100,CVE-2016-4110,CVE-2016-1104,CVE-2016-1103,CVE-2016-1102,CVE-2016-1101,CVE-2016-1108,CVE-2016-4115,CVE-2016-1107,CVE-2016-4116,CVE-2016-1106,CVE-2016-4117,CVE-2016-1105,CVE-2016-1109,CVE-2016-4160,CVE-2016-4161,CVE-2016-1096,CVE-2016-4162,CVE-2016-1099,CVE-2016-1110,CVE-2016-4163,CVE-2016-1098,CVE-2016-4120,CVE-2016-1097,CVE-2016-4121,CVE-2016-4108,CVE-2016-4109,10.20.120.12"
"CVE-2017-3099,CVE-2017-3100,CVE-2017-3080,10.20.120.12"
"CVE-2018-4878,CVE-2018-4877,10.20.120.12"
"CVE-2018-12824,CVE-2018-12825,CVE-2018-12826,CVE-2018-12827,CVE-2018-12828,10.20.120.12"
"CVE-2019-7845,10.20.120.12"
"CVE-2013-2470,CVE-2013-2450,CVE-2013-2472,CVE-2013-2471,CVE-2013-2412,CVE-2013-2456,CVE-2013-3744,CVE-2013-2455,CVE-2013-2458,CVE-2013-1500,CVE-2013-2457,CVE-2013-3743,CVE-2013-2452,CVE-2013-2451,CVE-2013-2473,CVE-2013-2454,CVE-2013-2453,CVE-2013-2437,CVE-2013-2459,CVE-2013-2461,CVE-2013-2460,CVE-2013-2445,CVE-2013-2467,CVE-2013-2400,CVE-2013-2444,CVE-2013-2466,CVE-2013-2447,CVE-2013-2469,CVE-2013-2446,CVE-2013-2468,CVE-2013-2463,CVE-2013-1571,CVE-2013-2462,CVE-2013-2443,CVE-2013-2465,CVE-2013-2442,CVE-2013-2464,CVE-2013-2449,CVE-2013-2448,CVE-2013-2407,10.20.120.210"
",10.20.120.233"
",10.20.120.233"
",10.20.120.233"
",10.20.121.134"
"CVE-2012-2311,CVE-2012-2335,CVE-2012-2336,10.20.121.14"
Is this what you're asking for? I hope so. ![]()
Ok, now I can confirm that your csv file doesn't actually contain comma-separated values but a single column of character strings so manual separation of the data is mandatory.
I would do it this way. Notice that I don't know what criteria to use to fill the missing CVE values so I left them as NA, I would need domain-specific knowledge of the data to figure that out.
library(dplyr)
library(tidyr)
sample_df <- read.csv("sample.csv", header = FALSE)
sample_df %>%
separate_rows(V1, sep = ",(?=CVE)") %>%
separate(V1, into = c("CVE", "IP"), sep = ",") %>%
fill(IP, .direction = "up")
#> # A tibble: 246 × 2
#> CVE IP
#> <chr> <chr>
#> 1 CVE-2004-2761 10.20.120.210
#> 2 CVE-2017-10081 10.20.120.210
#> 3 CVE-2017-10078 10.20.120.210
#> 4 CVE-2017-10111 10.20.120.210
#> 5 CVE-2017-10114 10.20.120.210
#> 6 CVE-2017-10135 10.20.120.210
#> 7 CVE-2017-10053 10.20.120.210
#> 8 CVE-2017-10074 10.20.120.210
#> 9 CVE-2017-10096 10.20.120.210
#> 10 CVE-2017-10110 10.20.120.210
#> # … with 236 more rows
Created on 2022-06-19 by the reprex package (v2.0.1)
Yeah, I don't get that, too. Apparently, that's how the tool creates de csv report. I've tried creating the report more than once, to no avail, the other options the tool provides (html and pdf) are too clogged and bloated for the data I need. Anyway, this will suffice I guess. I'll try to produce a new csv and open directly in R, this one I first opened in excel even though the tool says opening in excel could break the file. Thanks again for your patience and for pointing me in the right direction, I was doing everything wrong ![]()
Close but no cigar.
How many column of data were you expecting? Currently i am trying to read the data in a couple of ways but I am ending up with a data frame and a tibble with 92 columns and 1 row of data which does not seem correct. How many column of data were you expecting?
library(tidyverse)
dat1 <- read_csv("scristiano1.csv", col_names = FALSE)
dat3 <- read.csv("scristiano1.csv", sep = ",", quote = '"',
header = FALSE)
I really do not what that those data are doing. Essentially the layout or formatting looks strange. The commas , and quotation marks " do not seem to make sense.
We have
"CVE-2004-2761,10.20.120.210"
enclosed by quotation marks but not followed by a comma but then we have this long series enclosed in quotation marks and each element separated within those quotation marks by a comma. By the way what is that? It does not conform to the pattern of the rest of the data. Oh, is that the the xlsx file name? How did it get in there?
Anyway, let's go back to your original xlsx screenshot. Line 1 has a large number of comma separated data points separated by commas. Are each data point in a separate cell or are 32 or 33 entries in a single cell?
"CVE-2017-10081,CVE-2017-10078,CVE-2017-10111,CVE-2017-10114,CVE-2017-10135,CVE-2017-10053,CVE-2017-10074,CVE-2017-10096,CVE-2017-10110,CVE-2017-10176,CVE-2017-10198,CVE-2017-10116,CVE-2017-10115,CVE-2017-10118,CVE-2017-10117,CVE-2017-10193,CVE-2 017-10090,CVE-2017-10101,CVE-2017-10145,CVE-2017-10067,CVE-2017-10089,CVE-2017-10243,CVE-2017-10125,CVE-2017-10102,CVE-2017-10086,CVE-2017-10121,CVE-2017-10087,CVE-2017-10109,CVE-2017-10108,CVE-2017-10105,CVE-2017-10104,CVE-2017-10107, 10.20.120.210"
The last value in the above does not match the CVE-9999-9999 pattern. Any particular reason?
Something I probably should have asked earlier, how was the data generated?
Is it possible that each row in the spreadsheet is a variable?
As andresrcs said some posts ago, the file doesn't contain comma separated values, it's a single column with character strings. That's how the tool generates a "csv" report and it even warns you the file will break if you open it in excel - and it actually does. Anyway, andresrcs solution worked like a charm, I still have to cope with the NA rows but now that it is tidy and organized, I exported it excel and can use filters to fill in the blank spaces with the missing CVEs.
You can definitely fill the missing CVE values from R, no need to go to excel for that, I didn't do it because I don't know what criteria to use to fill them. If you can explain what criteria you are using, I can help you to implement it in R.
I was thinking about doing it manually but now that I've taken a deeper look at the document, I realized there are too many blank spaces for the job. I'm still thinking about a strategy, I know the report in pdf has the complete info but as I've said before, the pdf is too bloated with other security info and differently from the csv, the tool doesn't allow me to select what info I want to include in the pdf report, it just gives me the full thing. I don't know what criteria to use because I don't know which cve is missing.