It seems that vfold can be used to specify the value of repeat and v.
I specified repeat when I was doing deep learning where I needed to specify the learning rate.
But what is the advantage of using it for models that do not use learning rate like lm and glm?
If you want to check the uncertainty of the coefficients of the parameters, I think the bootstrap method is more computationally efficient than random sampling using vfold.
Agreed. If you want to get better estimates of how well the model works (e.g. RMSE or accuracy), any resampling method can be used but V-fold CV has better properties than the bootstrap (IMO). The bootstrap is terribly biased for performance estimation.
Thank you for helping me so often.
I'm not a native English speaker, and I'm not very good at English, so I know it's hard for you to read, but thank you for reading my question.
I would like to ask you an additional question because there is something I don't understand about your answer.
When I have been doing deep learning, I have been using each split of v-fold data as a mini-batch and letting it update the parameters.
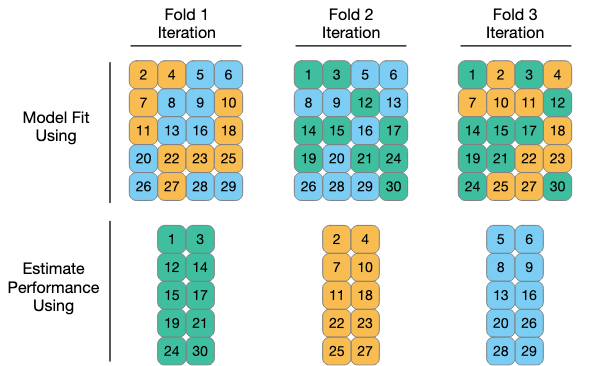
Do you mean that vfold in tidymodels is not treated as a mini-batch.
and if it is 10-fold, it is executed as 10 independent hold out methods?
By finding the average of the results of that evaluation, do you mean that it will work more accurately than 10 times bootstrapping data for the purpose of calculating how well the model is likely to FIT the data?
No. Min-batches all contribute to the final model fit. Resampling methods fit separate models and these are only used to measure performance. Once resampling is finished, the individual models are discarded.
Different resampling methods are statistical methods for estimating performance. Each has different properties. V-fold CV has better bias properties than the bootstrap. This means that the bootstrap is estimating something that may not be very close to the true, underlying performance value.
However, the variance of the bootstrap is very small (compared to V-fold CV). However, if the variance of CV is higher than you would like it to be, we can do repeats of CV to drive the variation down. The same approach does not help get rid of bias.
This blog post is a bit long but helps explain the difference.