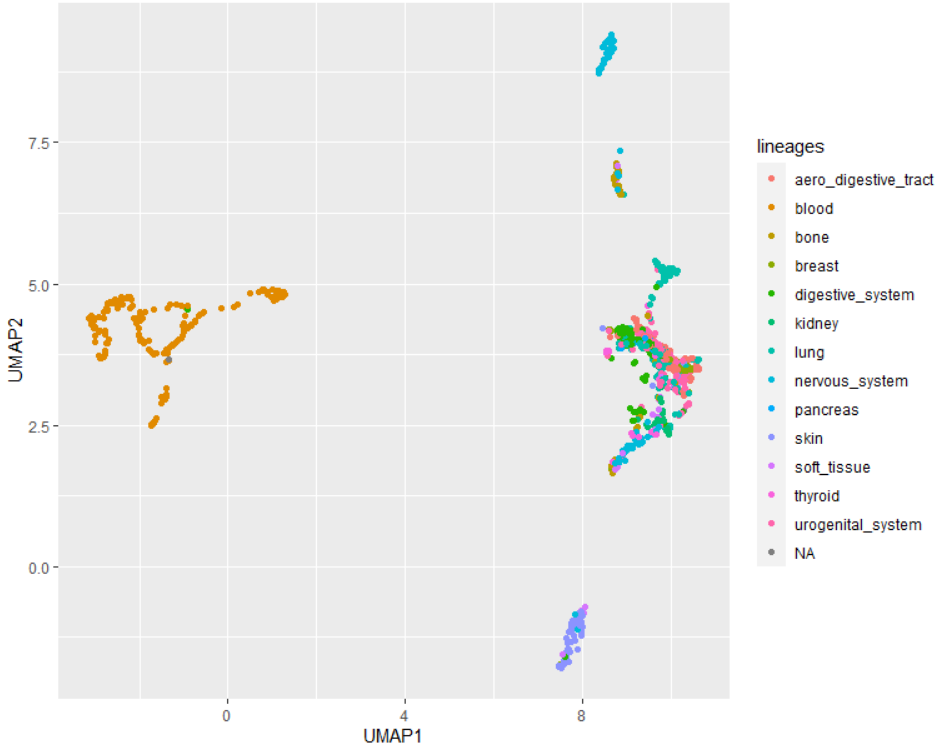
I have some gene expression data from various tissue types. I first wanted to use R to make a UMAP, and followed this wonderful and simple tutorial on how to do so using the umapr package.
My challenge is, however, that I've been asked to optimize this plot such that there is a maximum separation of the tissue types. In other words - is there any parameter than can be tweaked such that other tissue types can be further separated/clustered for maximum isolation?
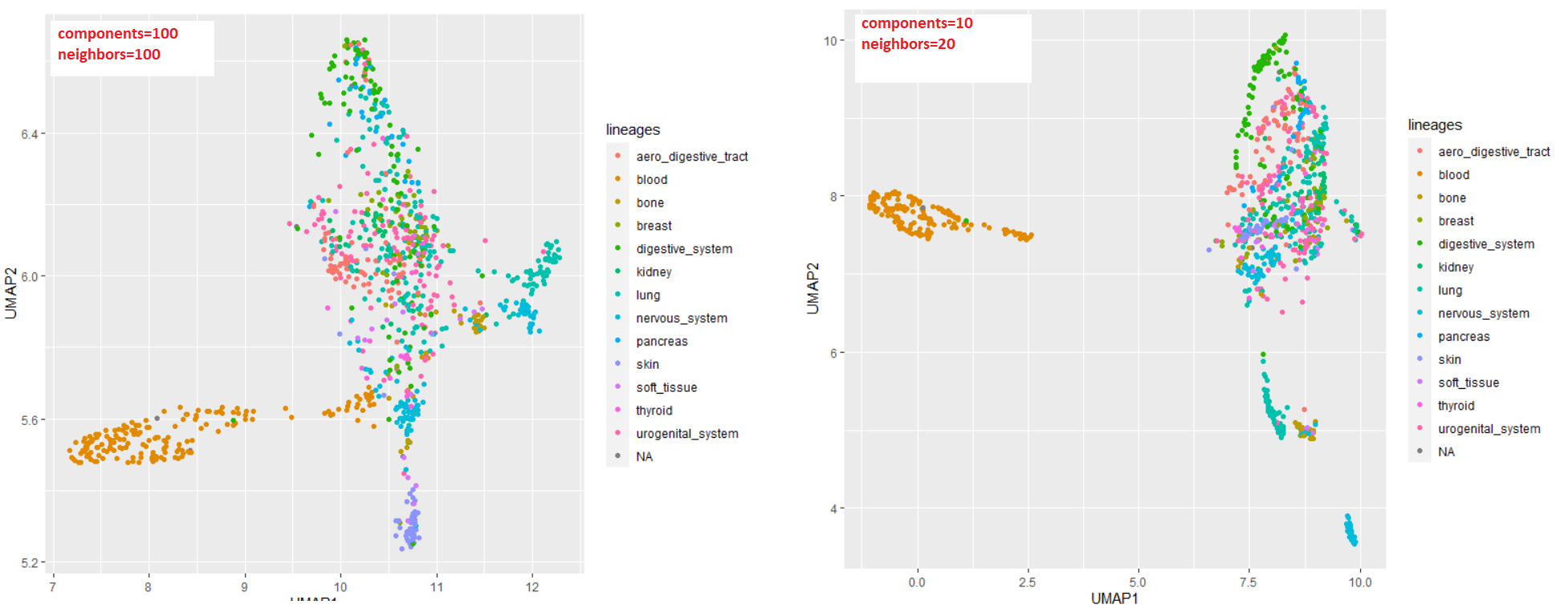
My issue is that I can tweak umapr's parameters like number of neighbors, number of components, number of training epochs, learning rate, etc etc....but testing all the combinations would take me until the end of time. This is an example of just tweaking two options, but there are millions of possible combinations when considering all paramters.
Looking at your plots, there is clearly a problem: the clusters do not match at all with the UMAP. The rectangle on the top-left of the graphs suggests you used 10-100 components, that means you projected on a UMAP space with 10-100 dimensions, here you're only visualizing 2 dimensions, there is no point in computing more. That hurts separation: if the clusters do separate along the 3rd dimension, they will not separate when plotting in 2D.
Another cause for the problem could be if you filtered a different number of PC before UMAP and clustering.
My experience in practice has been to tweak the parameters by hand, after reading about their effect. So if you want more separation, you typically need to reduce the number of neighbors and the minimum distance.
If you really want to do an optimization, it seems possible, but requires quite a bit of work, I don't think I've ever heard of people doing this for scRNA-Seq data (and I don't know of available libraries).
Finally, are you really sure it's worth the effort to get something really optimal? Typically with scRNA-Seq you just show the UMAP once so that everyone is happy to see it, then you work with the clustering that has been computed by a different algorithm (Louvain in the case of Monocle and Seurat).