I copied the data you posted into a file and separated the columns with commas. I had to guess at the column names. Using that data and the code you posted, I get the following.
library(ggplot2)
slid3 <- read.csv("~/R/Play/Dummy.csv")
head(slid3)
#> Description_Name V1 V2 Quantity Country_Name
#> 1 CARD PARTY GAMES 12 0.42 12433 Norway
#> 2 CARD PARTY GAMES 12 0.42 14829 United Kingdom
#> 3 CARD PARTY GAMES 12 0.42 12433 Norway
#> 4 CARD PARTY GAMES 12 0.42 16686 United Kingdom
#> 5 CARD PARTY GAMES 12 0.42 18245 United Kingdom
#> 6 CARD PARTY GAMES 12 0.42 12947 United Kingdom
slid3 |>
ggplot(aes(Country_Name, Quantity,
colour = Description_Name)) +
geom_point(size = 3, alpha = 0.5) +
geom_line(colour = "red") +
geom_smooth(method = "lm", se = F) +
theme_bw() +
labs(title = "Card Party Games Sales Distribution")
#> `geom_smooth()` using formula 'y ~ x'
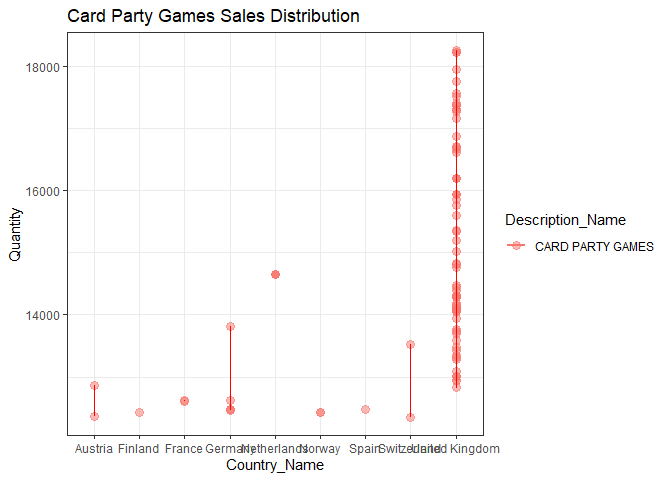
Created on 2021-11-02 by the reprex package (v2.0.1)
How would you like that to be different?
To post data in a copy-friendly way, you can use the dput() function. Below is the dput() output for the first ten rows of the data.
> dput(head(slid3,10))
structure(list(Description_Name = c("CARD PARTY GAMES ", "CARD PARTY GAMES ",
"CARD PARTY GAMES ", "CARD PARTY GAMES ", "CARD PARTY GAMES ",
"CARD PARTY GAMES ", "CARD PARTY GAMES ", "CARD PARTY GAMES ",
"CARD PARTY GAMES ", "CARD PARTY GAMES "), V1 = c(12L, 12L, 12L,
12L, 12L, 12L, 12L, 12L, 12L, 12L), V2 = c(0.42, 0.42, 0.42,
0.42, 0.42, 0.42, 0.42, 0.42, 0.42, 0.42), Quantity = c(12433L,
14829L, 12433L, 16686L, 18245L, 12947L, 12484L, 17555L, 15023L,
13742L), Country_Name = c("Norway", "United Kingdom", "Norway",
"United Kingdom", "United Kingdom", "United Kingdom", "Spain",
"United Kingdom", "United Kingdom", "United Kingdom")), row.names = c(NA,
10L), class = "data.frame")
The structure() function in that output can be copied into a script and its returned value is a data frame of the first 10 rows.