Hi all,
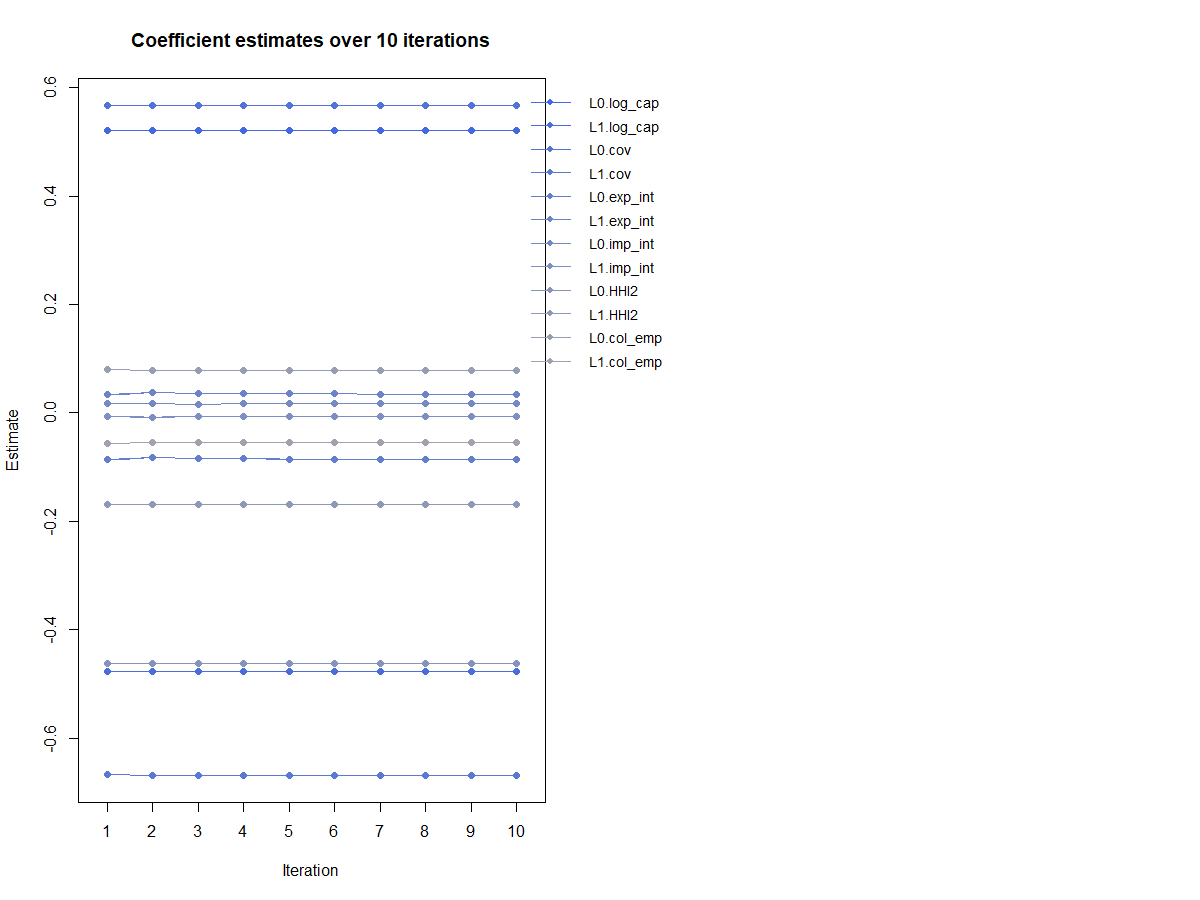
I am new to Dynamic panel data modelling. Basically I have a regression specification where I lag the dependent variable by one year and use the lags of all the other independent variables. This is in an industry time panel with 30 years and 18 industries. Although the coefficients are significant, I am having trouble with two things : 1) The coefficients alter in sign, the lagged effect is negative if the contemporary period estimate is positive and this happens for most of the variables in question. 2) How do I interpret the results in coefficient estimates and plots. I used plot(reg,type="coef.path",omit1step=TRUE, co=c("L0." "L1".)) and so on. The graph it produces is attached below. What does it mean when after 10 iterations each coefficient does not differ much. Does this say something about permanent effects of some of these variables, does it indicate that the estimates do not converge ? Most of my analysis is done using this link : https://cran.r-project.org/web/packages/pdynmc/vignettes/pdynmc-pres-in-a-nutshell.pdf
There don't seem to be many people participating in this community who work in econometrics, so you may get more specific advice asking elsewhere. For anyone working in general data science or statistics my best advice is to flee from "panel data", the econometrician term for what is known otherwise as a "time series."
My own take after reading the release paper pdynmc: A Package for Estimating Linear Dynamic Panel Data Models Based on Nonlinear Moment Conditions, I'm quite skeptical based on their use of
data(EmplUK, package = "plm")
to validate their model.
This is a partially incomplete ("unbalanced") collection of time series of economic measures of output, employment, wages and capital from 140 companies in 9 sectors over 8 years.
Let's look at one of the cases that does have complete data.
library(fpp3)
#> ── Attaching packages ────────────────────────────────────────────── fpp3 0.5 ──
#> ✔ tibble 3.2.1 ✔ tsibble 1.1.3
#> ✔ dplyr 1.1.2 ✔ tsibbledata 0.4.1
#> ✔ tidyr 1.3.0 ✔ feasts 0.3.1
#> ✔ lubridate 1.9.2 ✔ fable 0.3.3
#> ✔ ggplot2 3.4.3 ✔ fabletools 0.3.3
#> ── Conflicts ───────────────────────────────────────────────── fpp3_conflicts ──
#> ✖ lubridate::date() masks base::date()
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ tsibble::intersect() masks base::intersect()
#> ✖ tsibble::interval() masks lubridate::interval()
#> ✖ dplyr::lag() masks stats::lag()
#> ✖ tsibble::setdiff() masks base::setdiff()
#> ✖ tsibble::union() masks base::union()
data(EmplUK, package = "plm")
summary(EmplUK)
#> firm year sector emp
#> Min. : 1.0 Min. :1976 Min. :1.000 Min. : 0.104
#> 1st Qu.: 37.0 1st Qu.:1978 1st Qu.:3.000 1st Qu.: 1.181
#> Median : 74.0 Median :1980 Median :5.000 Median : 2.287
#> Mean : 73.2 Mean :1980 Mean :5.123 Mean : 7.892
#> 3rd Qu.:110.0 3rd Qu.:1981 3rd Qu.:8.000 3rd Qu.: 7.020
#> Max. :140.0 Max. :1984 Max. :9.000 Max. :108.562
#> wage capital output
#> Min. : 8.017 Min. : 0.0119 Min. : 86.9
#> 1st Qu.:20.636 1st Qu.: 0.2210 1st Qu.: 97.1
#> Median :24.006 Median : 0.5180 Median :100.6
#> Mean :23.919 Mean : 2.5074 Mean :103.8
#> 3rd Qu.:27.494 3rd Qu.: 1.5010 3rd Qu.:110.6
#> Max. :45.232 Max. :47.1079 Max. :128.4
# arbitrary example
d <- EmplUK[70:77,]
summary(d)
#> firm year sector emp wage
#> Min. :10.00 Min. :1976 Min. :3.0 Min. :1.158 Min. :20.23
#> 1st Qu.:11.00 1st Qu.:1978 1st Qu.:3.0 1st Qu.:1.242 1st Qu.:22.45
#> Median :11.00 Median :1980 Median :3.0 Median :1.342 Median :22.82
#> Mean :10.88 Mean :1979 Mean :3.5 Mean :1.532 Mean :23.32
#> 3rd Qu.:11.00 3rd Qu.:1981 3rd Qu.:3.0 3rd Qu.:1.355 3rd Qu.:24.52
#> Max. :11.00 Max. :1982 Max. :7.0 Max. :3.262 Max. :26.04
#> capital output
#> Min. :0.4099 Min. : 99.29
#> 1st Qu.:0.4725 1st Qu.: 99.67
#> Median :0.5354 Median :102.38
#> Mean :0.5826 Mean :103.90
#> 3rd Qu.:0.5779 3rd Qu.:107.84
#> Max. :1.0958 Max. :111.56
# pick another because this firm
# changed sectors
# this firm is entirely within the same
d <- EmplUK[15:21,]
summary(d)
#> firm year sector emp wage
#> Min. :3 Min. :1977 Min. :7 Min. :16.85 Min. :20.69
#> 1st Qu.:3 1st Qu.:1978 1st Qu.:7 1st Qu.:18.64 1st Qu.:21.70
#> Median :3 Median :1980 Median :7 Median :19.44 Median :22.69
#> Mean :3 Mean :1980 Mean :7 Mean :19.04 Mean :23.63
#> 3rd Qu.:3 3rd Qu.:1982 3rd Qu.:7 3rd Qu.:19.73 3rd Qu.:24.86
#> Max. :3 Max. :1983 Max. :7 Max. :20.24 Max. :28.91
#> capital output
#> Min. :5.715 Min. : 95.71
#> 1st Qu.:6.434 1st Qu.: 97.99
#> Median :6.856 Median : 99.56
#> Mean :6.690 Mean : 98.78
#> 3rd Qu.:7.022 3rd Qu.: 99.82
#> Max. :7.343 Max. :100.55
# remove firm and sector variable
# because values are constant
d <- d[,-c(1,3)]
# create a tsibble time series
ds <- as_tsibble(d, index = year)
autoplot(ds,.vars = emp) + theme_minimal()
autoplot(ds,.vars = wage) + theme_minimal()
autoplot(ds,.vars = capital) + theme_minimal()
autoplot(ds,.vars = output) + theme_minimal()
# correlations
GGally::ggpairs(d[,-1])
#> Registered S3 method overwritten by 'GGally':
#> method from
#> +.gg ggplot2
# fit a time series linear regression model
# fully saturated
fit <- ds |> model(TSLM(output ~ emp + wage + capital))
# results
report(fit)
#> Series: output
#> Model: TSLM
#>
#> Residuals:
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 55.8913 39.5774 1.412 0.253
#> emp 1.4265 1.3052 1.093 0.354
#> wage 0.7101 0.5349 1.327 0.276
#> capital -0.1579 1.4220 -0.111 0.919
#>
#> Residual standard error: 1.888 on 3 degrees of freedom
#> Multiple R-squared: 0.3882, Adjusted R-squared: -0.2236
#> F-statistic: 0.6345 on 3 and 3 DF, p-value: 0.64117
# residuals are normally distributed and
# no autocorrelation in the residuals
fit |> gg_tsresiduals()
# appears to be homoskedastic
ds |>
left_join(residuals(fit), by = "year") |>
pivot_longer(emp:capital,
names_to = "regressor", values_to = "x") |>
ggplot(aes(x = x, y = .resid)) +
geom_point() +
facet_wrap(. ~ regressor, scales = "free_x") +
labs(y = "Residuals", x = "")
augment(fit) |>
ggplot(aes(x = .fitted, y = .resid)) +
geom_point() + labs(x = "Fitted", y = "Residuals")
augment(fit) |>
ggplot(aes(x = year)) +
geom_line(aes(y = output, colour = "Data")) +
geom_line(aes(y = .fitted, colour = "Fitted")) +
labs(y = NULL,
title = "TSML Model of Output"
) +
scale_colour_manual(values=c(Data="black",Fitted="#D55E00")) +
guides(colour = guide_legend(title = NULL))
augment(fit) |>
ggplot(aes(x = output, y = .fitted)) +
geom_point() +
labs(
y = "Fitted (predicted values)",
x = "Data (actual values)",
title = "Output"
) +
geom_abline(intercept = 0, slope = 1)
Created on 2023-09-06 with reprex v2.0.2
That's not an encouraging start to putting this together with 139 other firms, many of which are in different sectors.
Without [a reprex (see the FAQ)(FAQ: How to do a minimal reproducible example ( reprex ) for beginners) I can't help you interpret your results, but I can't say I'm surprised that they should appear non-sensical.
Apologies to any econometricians who run across this. I'd rather be shown wrong than believe that panel data as practiced in your field is magical thinking. Convince me?
Maybe you could tell us more explicitly what equation you are estimating.
The econometrician’s term for “time series” is “time series.” “Panel data” refers to data which has both a time series and cross-section aspect. The best known example in economics is probably the Panel Study of Income Dynamics (PSID) which follows several thousand families over several decades.
Ah, you must be initiated into the mystery! Take a look at the paper and let me know what you think?
The paper is aimed at people with PhD level training in econometrics. For that, it’s quite good. It doesn’t seem to aim to be helpful to people from outside the area.
Hi @startz . Thank you for your reply. So basically I have a small panel (18 subsectors of Manufacturing over 28 years). I am trying to look at the determinants of labor share(dependent variable constructed as wages divided by value added) at the subsector level (for each 3 digit subsector such as Food and Tobacco products etc.). I am trying to examine the relative impact of capital intensity (proxied with capital stock to employment), import share, export share and decline in unionization coverage (independent vars). With an OLS and FE estimator (controlling for time and subsector specific FEs) I get decent results that are interpretable without any big change in sign or magnitudes. However, with the literature review I have, mostly lagged values of the dependent variable are used in any econometric specification. This leads me towards dynamic panel methods (although I am also looking at Least squares dummy with bias correction, which I don't have a good source to find).
Thank you @technocrat . I understand the issues with panel estimation(time series with different cross sectional units), especially with so many confounders. I did manage to understand why the current plot was producing these straight lines, that's because this code has an option to use non linear vs linear estimation methods. WIth linear estimation there is no convergence.
So if y is the dependent variable and x is (one of the) independent variables is the specification roughly
y_t=\beta_0 + \beta_1 \times x_t + \lambda \times y_{t-1} +\epsilon_t ?
And the problem is estimated \lambda is negative?
And are you including lags of the dependent or the independent variables for the other industries?
Yes ! this equation is right . Except that I have more than one x variable. Im lagging the dependent variable and the independent variables. The problem is that lagged independent variables (or lag x terms) the coefficients alter in sign. As in x(t) is has a positive coefficient but x(t-1) has a negative coefficient. In these cases what would be a good interpretation ? I can simply say that lagged term has a negative effect and contemporary term has a positive effect but that won't really say anything much. I have tried lagging just the dependent variable (without lags of x) but that doesn't give such good results.
In principle, if the coefficient on x(t) is positive and on x(t-1) is negative that says that a sustained change in x does some overshooting. Suppose the coefficients are 1 and -0.25. Then after a sustained increase of 1 in x, y goes up first by1 but after the second period is only 1-0.25=0.75 above the original level,
But if you only have 28 years and you have both contemporaneous and lagged coefficients on 18 industries you would have more coefficients than observations. So I’m missing something.
Thank you so much for this! Would you suggest sticking to the results from the Fixed effects specs. I have also tried FE with just one lagged y (like the equation you mentioned above). I do get more interpretable results that the literature review supports. But they say that with lagged dependent vars, FEs are biased.
I don’t know enough about the application to give good advice I’m afraid.
The literature does strike me as somewhat like a clubhouse. ![]()
There don't seem to be many people participating in this community who work in econometrics, so you may get more specific advice asking elsewhere. For anyone working in general data science or statistics my best advice is to flee from "panel data", the econometrician term for what is known otherwise as a "time series."
This topic was automatically closed 42 days after the last reply. New replies are no longer allowed.
If you have a query related to it or one of the replies, start a new topic and refer back with a link.