I am trying to interpret a MARs model for classification.
Below is an example taken from the recipes package where I'm trying to predict the factor Status
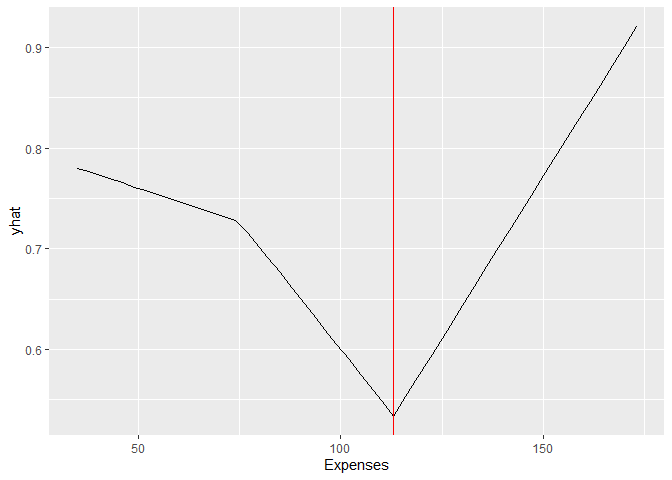
Taking the field Expenses as an example, how do I read/interpret the co-efficent attached to Expenses-113 - 0.0102 and where in my diagram can I see this? Is this everything to the right of my red vertical line (set at 113).
The next question is related to the intercept. If my model below the intercept is set to 0.985
Does this mean on average someone in my dataset is 98.5% likely to be a good customer?
In that case are the co-efficents in reference to the intercept or am I talking out of my hat
Thank you very much for your time. Have a nice weekend
suppressPackageStartupMessages(library(tidyverse))
#> Warning: package 'tidyverse' was built under R version 3.5.2
#> Warning: package 'ggplot2' was built under R version 3.5.3
#> Warning: package 'tibble' was built under R version 3.5.2
#> Warning: package 'readr' was built under R version 3.5.2
#> Warning: package 'purrr' was built under R version 3.5.2
#> Warning: package 'dplyr' was built under R version 3.5.2
#> Warning: package 'stringr' was built under R version 3.5.2
#> Warning: package 'forcats' was built under R version 3.5.2
suppressPackageStartupMessages(library(earth))
#> Warning: package 'earth' was built under R version 3.5.2
#> Warning: package 'plotmo' was built under R version 3.5.2
#> Warning: package 'plotrix' was built under R version 3.5.2
suppressPackageStartupMessages(library(recipes))
#> Warning: package 'recipes' was built under R version 3.5.1
mydf <- credit_data %>%
na.omit()
table(mydf$Status)
#>
#> bad good
#> 1026 3013
mars_mod <- earth(Status~., mydf)
coefficients(mars_mod) %>%
enframe() %>%
arrange(desc(abs(value)))
#> # A tibble: 19 x 2
#> name value
#> <chr> <dbl>
#> 1 (Intercept) 0.985
#> 2 Recordsyes -0.283
#> 3 Jobpartime -0.243
#> 4 Maritalseparated -0.159
#> 5 Homepriv -0.0838
#> 6 Homeparents 0.0618
#> 7 h(4-Seniority) -0.0328
#> 8 h(Expenses-113) 0.0102
#> 9 h(Seniority-18) -0.00984
#> 10 h(Seniority-4) 0.00840
#> 11 h(Expenses-75) -0.00375
#> 12 h(130-Income) -0.00319
#> 13 h(Age-19) -0.00137
#> 14 h(113-Expenses) 0.00133
#> 15 h(Amount-475) -0.000276
#> 16 h(1175-Price) -0.000221
#> 17 h(Price-1175) 0.0000745
#> 18 h(2432-Debt) 0.0000368
#> 19 h(5500-Assets) -0.0000291
# Now we build up the PDP Plots
yhat_earth <- function(object, newdata) as.numeric(predict(object, newdata, type = "response"))
# TO confirm we are predicting the Yes label
predict(mars_mod, mydf, type = "response") %>% head(10)
#> good
#> [1,] 0.8289485
#> [2,] 0.9477466
#> [3,] 0.4210298
#> [4,] 0.8097659
#> [5,] 0.7307951
#> [6,] 0.9320309
#> [7,] 0.9131152
#> [8,] 0.9330565
#> [9,] 0.6851392
#> [10,] 0.2086033
# Expenses-113 - 0.0102, 113-Expenses - 0.00133
pdp::partial(mars_mod, pred.var = "Expenses", grid.resolution = 50) %>%
autoplot() +
geom_vline(xintercept = 113, colour = "red")
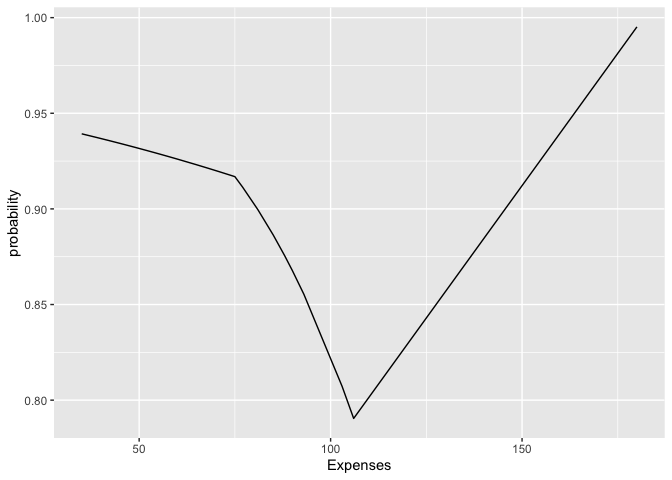
The coefficients are on the log-odds scale (basically logistic regression with MARS features). So an intercept of 0.985 translate to a probability of binomial()$linkinv(0.985) = 0.7280992.
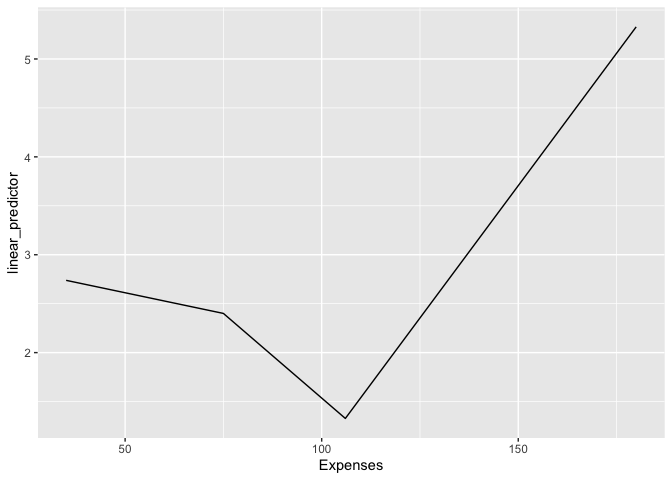
The plot is also on the log-odds scale (otherwise the lines would be curved).
Thank you for the quick reply. If i may just follow up with two questions
The coefficient Expenses-113 0.0102 says that where the Expenses are greater than 113, the log odds of being a good customer are increased by 0.0102 and this is represented by the right hand side of the graph? Where does the coefficent 14 h(113-Expenses) 0.00133 sit on the graph?
I have set yhat for the y axis, but if i wanted to set the probability instead of the log odds, I could set that in my yhat_earth formula? I assume this holds for all other models I use as well?
So before we talk about that, you need to fit this model differently for a qualitative outcome. I just noticed that you should have used the option glm = list(family = binomial). The splits are about the same but the coefficients are different:
That gets complicated. The profile for Expenses uses the intercept and three of the terms (you have two breakpoints at 113 and 75). The different segments are combinations of different slopes for the features.
h(Expenses-75) has a negative slope of -0.0261 which affects values > 75
h(Expenses-113) has a positive slope of 0.0894 which affects values > 113
h(113-Expenses) has a positive slope of 0.00845 which affects values < 113
so that :
< 75 slope is -0.0261
75 - 113 slope is 0.00845 - 0.0261 = -0.01765
> 113 slope is 0.0894 - 0.0261 = 0.0633
Finally, note that the intercept term in these plots is arbitrary and would change for different values of the other predictors. The slopes would not change though (since this is an additive model - no interactions).