I am working on using a wine quality dataset (Wine Quality Dataset | Kaggle)
using the alcohol content as the dependent variables
I am creating a manual regression model - IE removing values I think have less impact and then comparing that to a Backwards stepwise regression to determine if my model is better than the created one.
Looking at pure F-stat values as well as R^2 and degrees of freedom I want to say that my model is better but I am having trouble interpreting the OLS graphs
My manual model has an F-stat of 374 with 1135 DF and a R^2 of .6968 where the stepwise regression has an F-stat of 274.4 with 1132 DF and a R^2 of .7086
I removed Chlorides, Free and Total Sulfur dioxide and the Stepwise model only removed Free Sulfur Dioxide
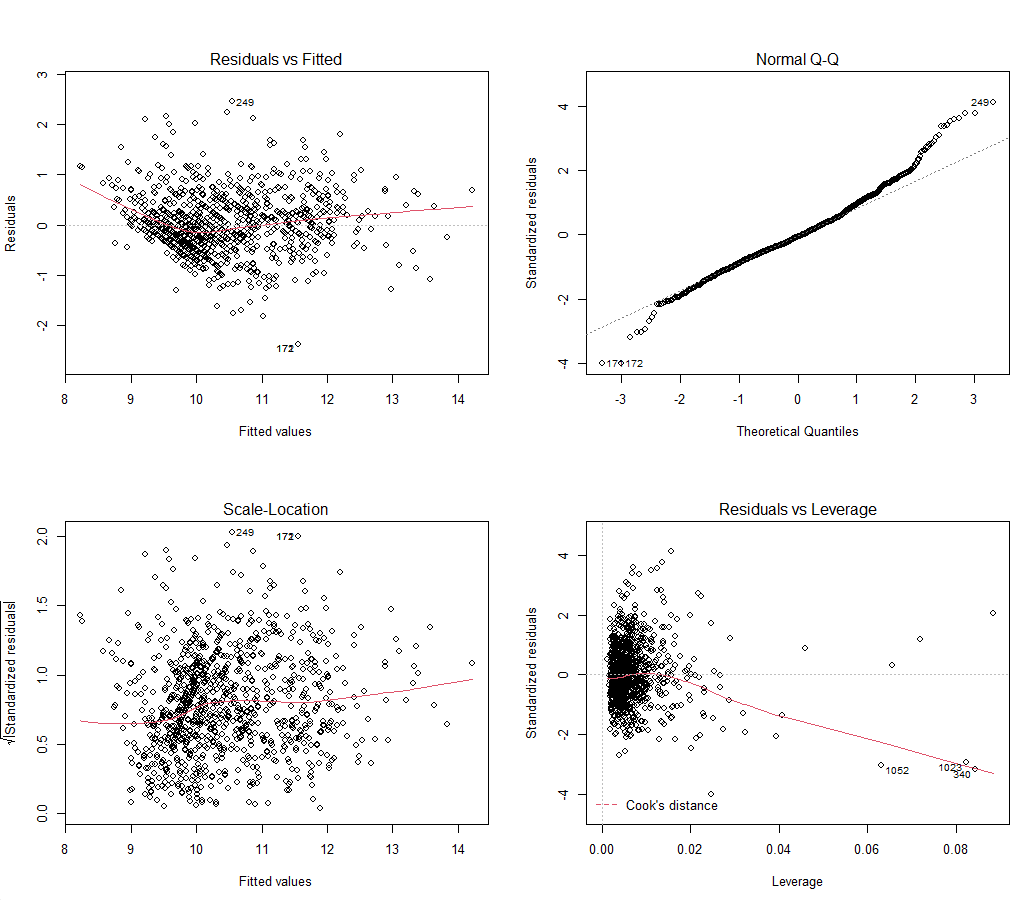
From what I understand - which is pretty basic as I am just learning the language;
Normality which is checked on the top right seems to be accurate until the top end with some outlier values
Linearity which is checked in the top Left seems to follow a semi linear pattern but there are a lot more outlier variables – the curve from the residual which seems to increase as the fitted Y value increases means we can assume that heteroscedasticity exists.
Looking at homoscedasticity on the bottom left we can see that it follows the median line pretty well with only some minor deviation – typically if we saw a random distribution of values and a flat red line, we are sure there is no heteroscedasticity – as this is not the case, we know that heteroscedasticity exists
As we see possibly outliers, we can say that the OLS assumptions are not met based on our testing.
but I am hoping that some of you with much more knowledge might be able to better explain what I am looking at