I actually know nothing about FactoMineR but it seems it doesn't like you to include id's, I hope this can help you
library(FactoMineR)
library(dplyr)
PrefEmp <- structure(list(Subject = 1:55, TV = c("Sport", "Comedy", "Drama",
"Films", "Films", "Drama", "Sport", "Nature", "Comedy", "News",
"Comedy", "Nature", "Drama", "Sport", "Drama", "Drama", "Police",
"Sport", "Films", "Nature", "Comedy", "Sport", "Drama", "Sport",
"Nature", "Comedy", "Police", "Sport", "Drama", "Comedy", "Comedy",
"Nature", "Comedy", "Drama", "Drama", "Police", "Drama", "Drama",
"Films", "Comedy", "Drama", "Drama", "Sport", "Sport", "Sport",
"Sport", "Drama", "Drama", "Comedy", "Drama", "Comedy", "Comedy",
"Drama", "Drama", "Comedy"), Film = c("SciFi", "Comedy", "Comedy",
"Action", "Documentary", "Documentary", "Comedy", "Comedy", "SciFi",
"SciFi", "Comedy", "Documentary", "CostumeDrama", "Comedy", "SciFi",
"SciFi", "Comedy", "Documentary", "Documentary", "SciFi", "Comedy",
"Comedy", "Action", "Comedy", "SciFi", "SciFi", "Action", "Documentary",
"Action", "Comedy", "Comedy", "Comedy", "Action", "SciFi", "CostumeDrama",
"Romance", "Comedy", "Action", "SciFi", "Comedy", "Action", "Documentary",
"Comedy", "Comedy", "Comedy", "Comedy", "SciFi", "Comedy", "Action",
"Action", "Comedy", "Romance", "Comedy", "Comedy", "Comedy"),
Art = c("Modern", "Landscape", "Impressionism", "Performance",
"Modern", "Performance", "Landscape", "Impressionism", "Modern",
"Impressionism", "Performance", "Modern", "Modern", "Landscape",
"Landscape", "Impressionism", "Performance", "Renaissance",
"Impressionism", "Landscape", "Performance", "Modern", "Landscape",
"Modern", "Landscape", "Landscape", "Impressionism", "Impressionism",
"Renaissance", "Impressionism", "Modern", "Landscape", "Performance",
"Impressionism", "Impressionism", "Landscape", "Renaissance",
"Performance", "Renaissance", "Impressionism", "Landscape",
"Modern", "Renaissance", "Renaissance", "Modern", "Performance",
"Impressionism", "Modern", "Landscape", "Modern", "Impressionism",
"Landscape", "Modern", "Modern", "Modern"), Restaurant = c("Italian",
"Italian", "French", "Indian", "SteakHouse", "SteakHouse",
"Pub", "Italian", "Burgers&Fries", "Pub", "Italian", "Indian",
"Italian", "Burgers&Fries", "Indian", "Italian", "French",
"Italian", "French", "Pub", "Italian", "Pub", "Pub", "Italian",
"SteakHouse", "SteakHouse", "Burgers&Fries", "Italian", "Italian",
"SteakHouse", "SteakHouse", "SteakHouse", "SteakHouse", "Indian",
"Italian", "Italian", "Italian", "Italian", "SteakHouse",
"Italian", "Italian", "Italian", "Italian", "Italian", "Burgers&Fries",
"Italian", "SteakHouse", "Indian", "Italian", "SteakHouse",
"Italian", "Pub", "Italian", "Italian", "Indian"), Gender = c("Male",
"Female", "Female", "Female", "Female", "Female", "Male",
"Male", "Male", "Male", "Female", "Male", "Female", "Male",
"Male", "Female", "Female", "Male", "Male", "Male", "Female",
"Female", "Male", "Male", "Male", "Male", "Male", "Male",
"Male", "Female", "Female", "Female", "Female", "Female",
"Female", "Female", "Male", "Female", "Male", "Female", "Female",
"Female", "Male", "Male", "Male", "Male", "Female", "Female",
"Female", "Male", "Male", "Female", "Female", "Female", "Male"
), Age = c("35 to 44", "45 to 54", "45 to 54", "45 to 54",
"35 to 44", "35 to 44", "45 to 54", "45 to 54", "35 to 44",
"55 to 64", "18 to 24", "35 to 44", "45 to 54", "35 to 44",
"45 to 54", "35 to 44", "25 to 34", "55 to 64", "45 to 54",
"55 to 64", "25 to 34", "45 to 54", "45 to 54", "45 to 54",
"45 to 54", "45 to 54", "65+", "45 to 54", "25 to 34", "45 to 54",
"35 to 44", "35 to 44", "25 to 34", "55 to 64", "35 to 44",
"45 to 54", "35 to 44", "35 to 44", "45 to 54", "25 to 34",
"35 to 44", "45 to 54", "25 to 34", "55 to 64", "25 to 34",
"45 to 54", "35 to 44", "45 to 54", "45 to 54", "45 to 54",
"55 to 64", "35 to 44", "45 to 54", "45 to 54", "45 to 54"
), Job = c("S&M", "R&D", "S&M", "R&D", "S&M", "R&D", "R&D",
"R&D", "R&D", "R&D", "R&D", "R&D", "S&M", "R&D", "R&D", "R&D",
"S&M", "R&D", "S&M", "R&D", "S&M", "R&D", "S&M", "S&M", "R&D",
"R&D", "R&D", "R&D", "R&D", "S&M", "S&M", "S&M", "R&D", "R&D",
"R&D", "R&D", "R&D", "R&D", "R&D", "S&M", "S&M", "S&M", "R&D",
"S&M", "R&D", "S&M", "R&D", "R&D", "S&M", "S&M", "R&D", "R&D",
"R&D", "S&M", "R&D")), class = "data.frame", row.names = c(NA,
-55L))
PrefEmp %>%
mutate(across(where(is.character), as.factor)) %>%
select(-Subject) %>%
MCA()
#> Warning: ggrepel: 22 unlabeled data points (too many overlaps). Consider
#> increasing max.overlaps
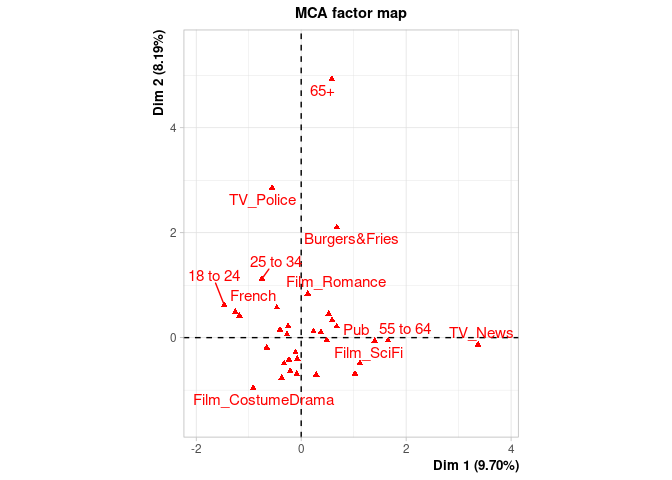

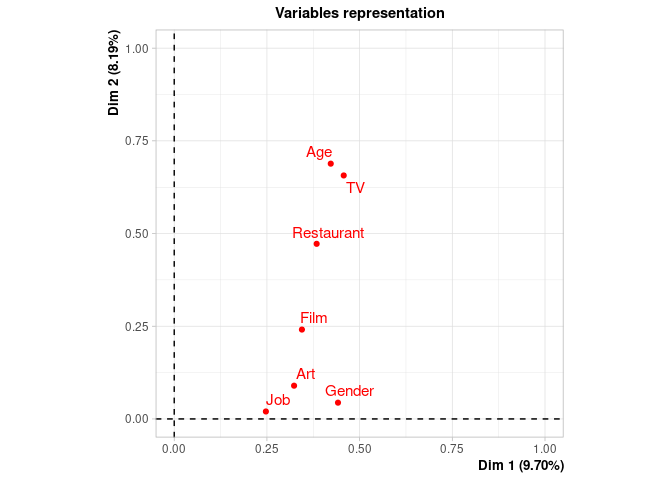
#> **Results of the Multiple Correspondence Analysis (MCA)**
#> The analysis was performed on 55 individuals, described by 7 variables
#> *The results are available in the following objects:
#>
#> name description
#> 1 "$eig" "eigenvalues"
#> 2 "$var" "results for the variables"
#> 3 "$var$coord" "coord. of the categories"
#> 4 "$var$cos2" "cos2 for the categories"
#> 5 "$var$contrib" "contributions of the categories"
#> 6 "$var$v.test" "v-test for the categories"
#> 7 "$ind" "results for the individuals"
#> 8 "$ind$coord" "coord. for the individuals"
#> 9 "$ind$cos2" "cos2 for the individuals"
#> 10 "$ind$contrib" "contributions of the individuals"
#> 11 "$call" "intermediate results"
#> 12 "$call$marge.col" "weights of columns"
#> 13 "$call$marge.li" "weights of rows"
Created on 2022-07-03 by the reprex package (v2.0.1)