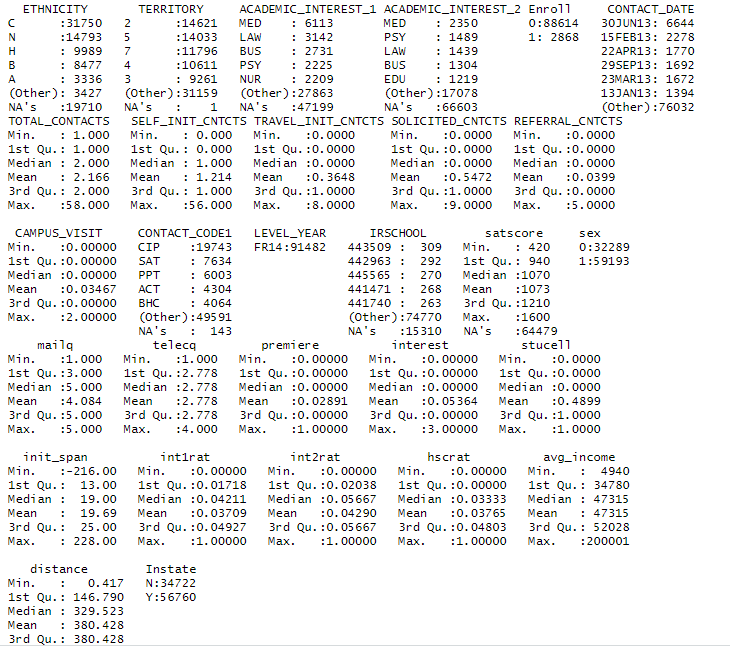
I am doing a school project and trying to clean up the data by normalizing and grouping the large-value-range variable to two-three classes. The original missing values of 'avg_income' already got imputed with its mean as it shown in the image above without any missing values.
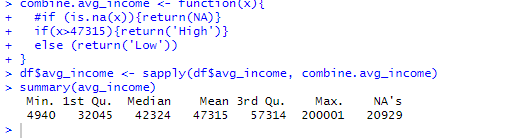
But when I run this function trying to group 'avg_income' into 'High' and 'Low' categories, it generated a lot of missing values.
Could anyone tell me the logic of why this happened?
Below are my codes following an image of summary of 'avg_income' after I run the function:
combine.avg_income <- function(x){
if (is.na(x)){return(NA)}
else if(x>47315){return('High')}
else (return('Low'))
}
Let's simulate your problem by reducing it to the basics.
You already have a variable, df$avg_income that's been scrubbed of NAs. I'm going to create a proxy from some made-up data and illustrate a tidy solution.
require(charlatan)
#> Loading required package: charlatan
require(dplyr)
#> Loading required package: dplyr
#>
#> Attaching package: 'dplyr'
#> The following objects are masked from 'package:stats':
#>
#> filter, lag
#> The following objects are masked from 'package:base':
#>
#> intersect, setdiff, setequal, union
require(tibble)
#> Loading required package: tibble
phony <- enframe(ch_integer(n = 50000, min = 4940, max = 2000001))
phony %>% select(-name) %>% rename(income = value) -> phony
mid <- median(phony$income)
phony %>% mutate(category = ifelse(income < mid, "low","high"))
#> # A tibble: 50,000 x 2
#> income category
#> <dbl> <chr>
#> 1 1724785 high
#> 2 1094812 high
#> 3 1322170 high
#> 4 1308088 high
#> 5 1066873 high
#> 6 1386093 high
#> 7 1616536 high
#> 8 180569 low
#> 9 123062 low
#> 10 1004668 high
#> # … with 49,990 more rows
Thanks a lot the quick response.
I will test out your code and see if it works for my case or not.
And thanks for the great tips of posting questions. I will definitely follow that if I have any questions next time.