Could you please turn this into a self-contained reprex (short for minimal reproducible example)? It will help us help you if we can be sure we're all working with/looking at the same stuff.
If you run into problems with access to your clipboard, you can specify an outfile for the reprex, and then copy and paste the contents into the forum.
Hi Mara, I am not sure to understand how to use reprex, i installed it but unable to copy the result that should be on clipboard
here is my program
# To clean up the memory of your current R session run the following line
rm(list=ls(all=TRUE))
# install.packages("devtools")
install.packages("devtools")
devtools::install_github("tidyverse/reprex")
# Let's load our dataset
data=read.csv('CO2_passenger_cars_v14.csv',header = TRUE, sep = ",", stringsAsFactors = FALSE)
when the file is imported it contains only one variable, while there should be 26 as when i open in excel, so I don't understand what is my mistake please.
thanks Mara, but I am not a programmer at all. I tried to figure out how to create what is a gist, then created an account but unable to upload the file on github.
do you have another alternative; sorry for boring.
Just to explain the reprex thing a bit more, and the notion of minimal reproducible examples: it looks like there are more than 400,000 records in the zip files you've linked to. Usually, if it's a problem in the code, one can reproduce it without having to deal with all 400,00+ records.
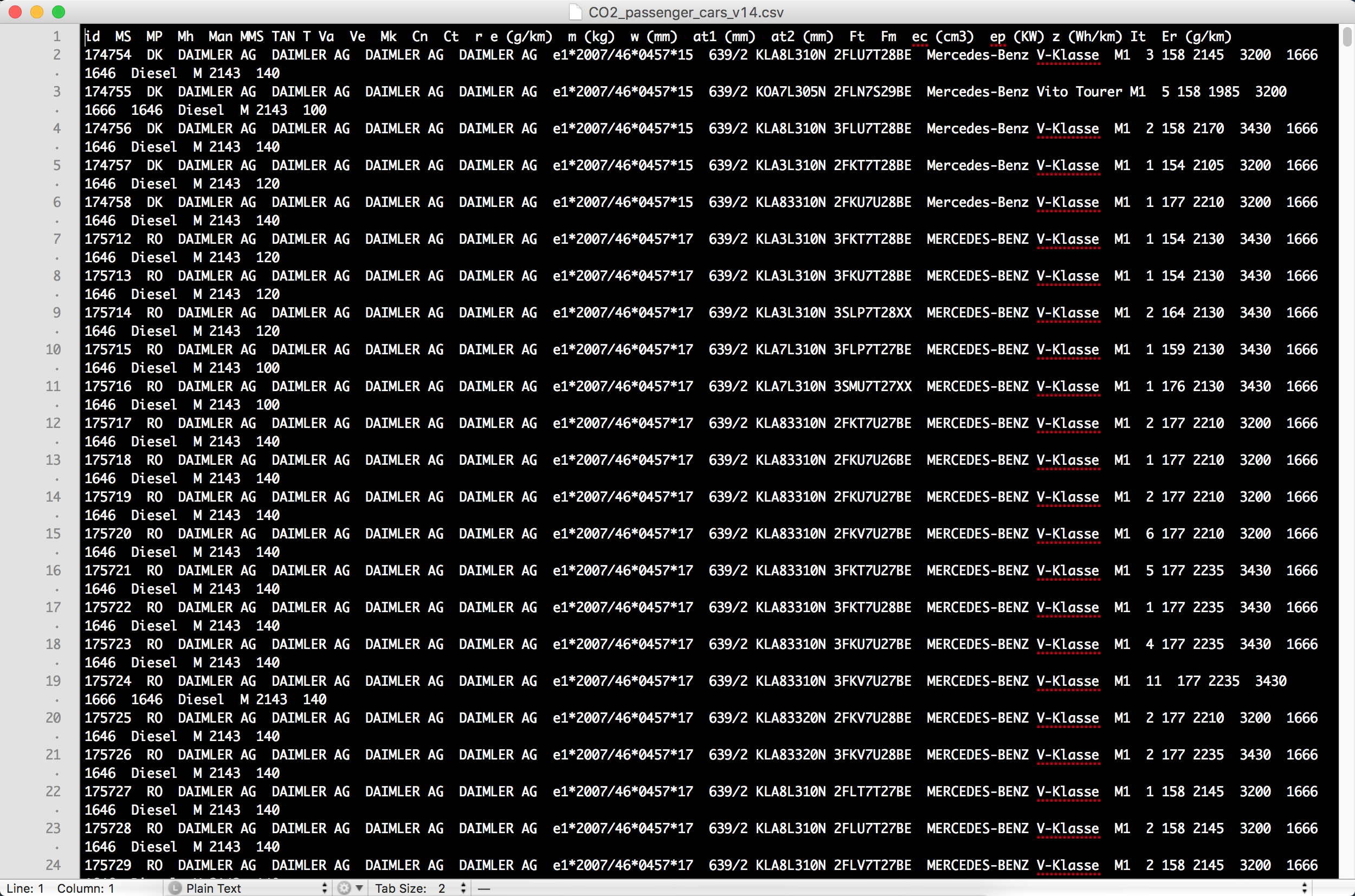
OK here's the problem: the csv is not actually a csv. So, in essence, this is a problem with the file itself. Below I'm describing how I figured this out, though I'm sure there are other ways to deal with this using base R, a text editor, etc.
In Excel it the file as though the file is a csv (I don't know the innards of Excel well-enough to know how this is accomplished), but, when you open the file in a text editor, you can see that there are not actually commas, there are tabs!
It also has some unusual encoding settings, so, when I re-saved it (file, save as) in a text editor, I switched the character encoding to UTF-8.
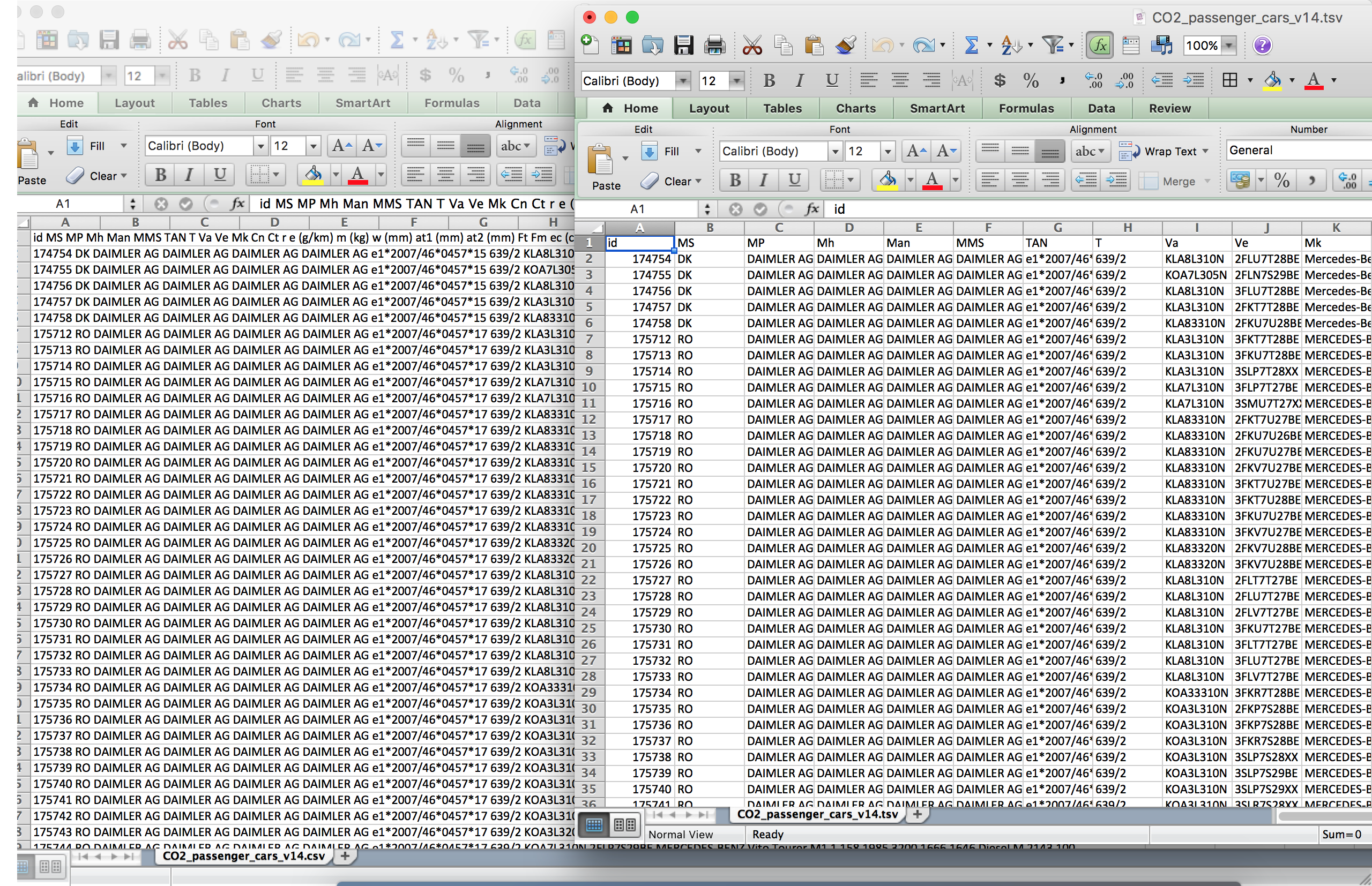
Below, see with encoding as UTF-8 and proper line endings in CSV file vs TSV.
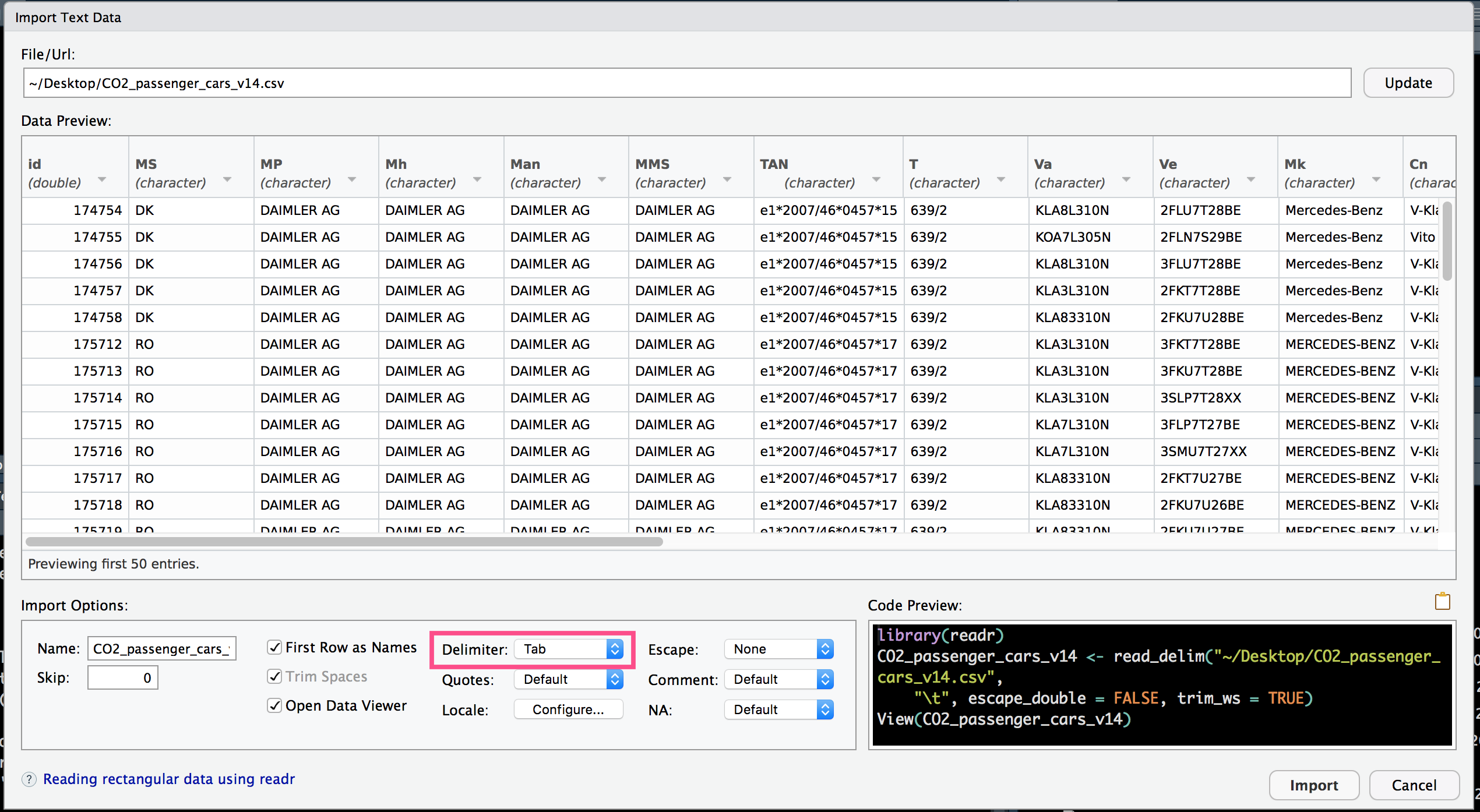
This might not be a great way to do it, but, this did allow me to at least see all of the data when I went to preview it in RStudio (you can't open the full file in the text editor because of the size, but I could see it all in File >> Import.
After switching the character and line-ending encodings in the text editor, I could see all of the rows, but they were prepared to import as a single column (because there were no actual commas). By switching the delimiter from comma to tab, it automatically changes the configuration (albeit using the readr package, as opposed to base read.csv).
Hey Mara, a small question question please. Is it possible to plot integer variable against character. for example I want to plot the CO2 emission against the country, to see if some countries have higher CO2 emission, when I plot this I got an error message that my variable is unknow or not initialised
also when i check the class(data) i get 3 classes is it normal?
class(data)
[1] "tbl_df" "tbl" "data.frame"