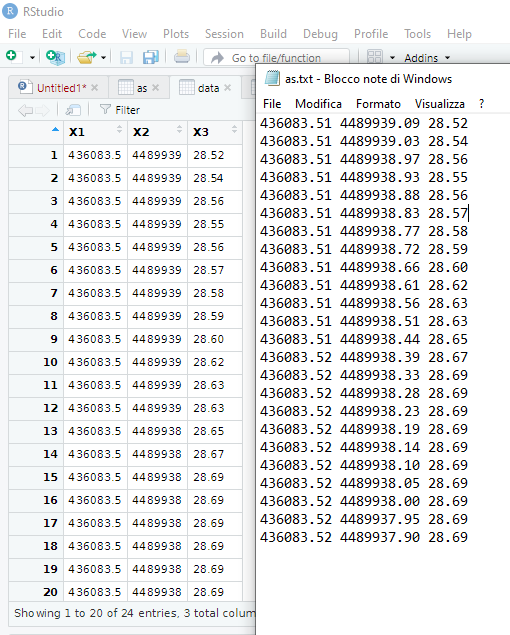
Hello, I am new of the community and a new of using R and Rstudio. I am trying to import a txt dataset but I receive an import different from the original table, to clarify I am importing a file with a row= 436083.51 4489939.09 28.52 and I receive in Rstudio 436083.5 4489939 28.52, loosing some numbers.
library(readr)
as <- read_table2("as.txt", col_names = FALSE)
What results do you get if you use read_table() instead of read_table2()? Since your data appears to be well-structured with a single space delimiting the values, you shouldn't need the latter.
nirgrahamuk is right. You aren't seeing enough significant digits in the Viewer pane which is controlled via options. For example, setting options(digits = 9) will work for your data.
Sorry, but I have starting to learn R yesterday and this is my first dataset import...I am not able to understand your solution, can you explain in a simple way?
you can run the entire script I posted and think about what its telling you.
There are options that control how R prints numbers.
Probably good options for your case might be
options(digits=9,scipen=999)
you can simply run that at the top of your script, and then continue to work as normal. If you want to see more or less significant digits , or change the likelihood of numbers appearing in scientific notation, you would change these options.
Hello,
now I am tring to save a txt file using write.table() but if I have a number with a 0 after the decimal separetor this is omissed in the output, for example if the data is 18.20 in the stored txt I got 18.2. I hope that this is clear.
Any help?