I am very new to using R and am trying to delete all rows from a dataframe after a time point where a condition is met, so for a particular column I wish to delete all rows if one date column is greater than the other date column only if another column does not have "None" in that row.
I have tried the script:
newdf <- for(df$ID in df)
if(df$Endpoint != "None" && df$VISITDATE>df$DATE)
drop(df$ID)
This throws me an error -
df$Endpoint != "None" && df$VISITDATE > :
'length(x) = 17012 > 1' in coercion to 'logical(1)'
I really appreciate any help on this as have been on so many forums and no luck so far! (the above code I tried also may be very wrong as I am so new to all this)
A handy way to supply some sample data is the dput() function. In the case of a large dataset something like dput(head(mydata, 100)) should supply the data we need.
I have never encountered drop before but it is not doing what you think it is. See
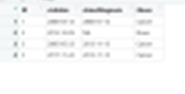
also typed out data frame below as upload is poor quality.
ID | visitdate | dateofdiagnosis | Illness
1 | 2000-03-12 | 2000-01-12 | Cancer
2 | 2013-12-05 | NA | None
3 | 2005-05-23 | 2013- 11-13 | Cancer
3 | 2017-11-22 | 2013-11-13 | Cancer
Hi,
Thank you for your help! I have uploaded above a demo df (Endpoint in above comment is now Illness column) - so through the code I am hoping to delete row 1 since the visitdate is later than the diagnosis date, leave in the second row since illness says "none", keep row 3 since visitdate is less than the date of diagnosis (so they weren't ill then), and delete row 4 which is the same ID but after the diagnosis. I hope this makes sense, so sorry!
I am open to use any script you may recommend, I tried the above through just scouting different forums for potential code.
It looks like you have done coding before. Abandon all that you know! R is seriously weird if you are familiar with "normal" programming or even other stats packages.