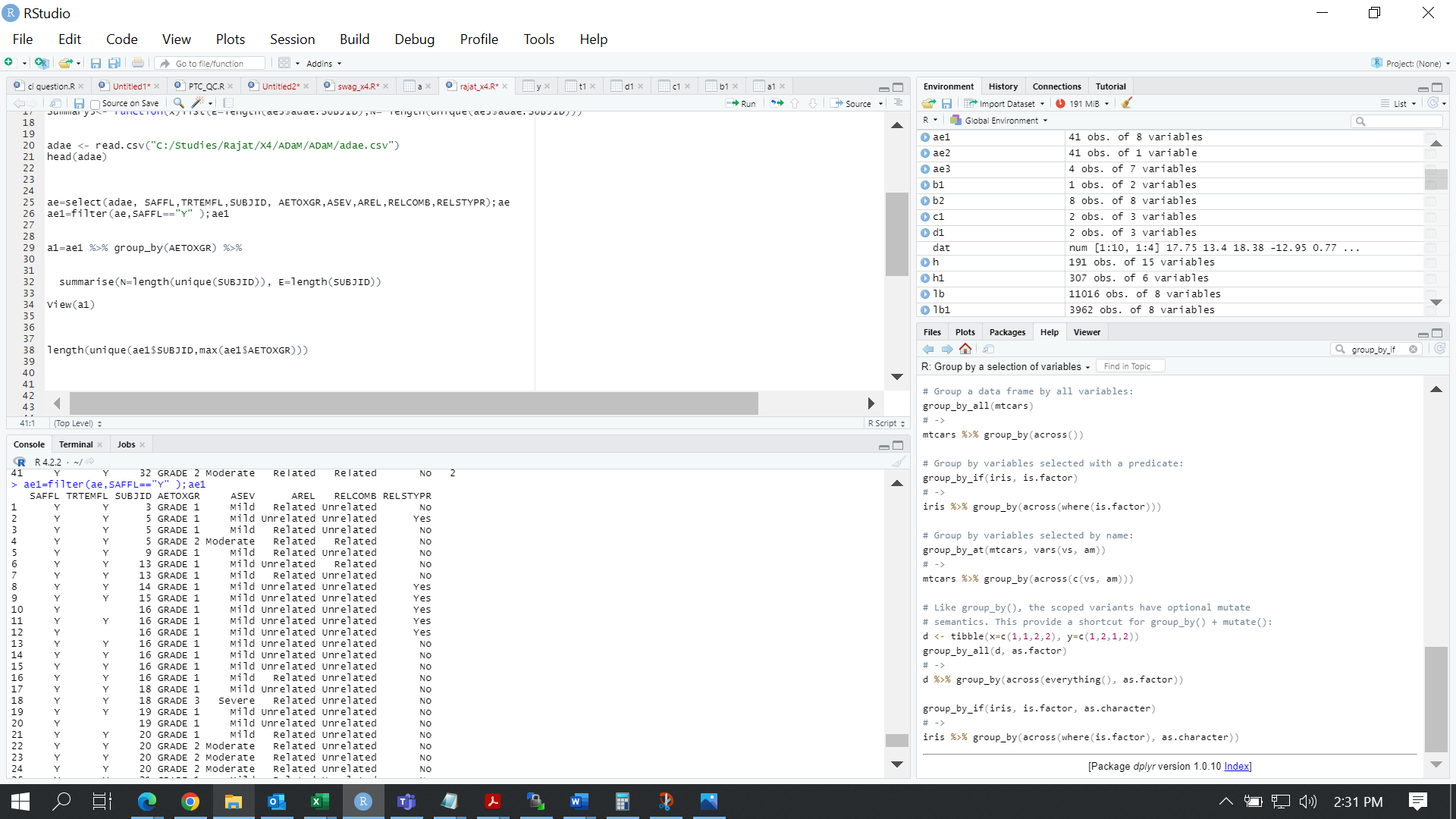
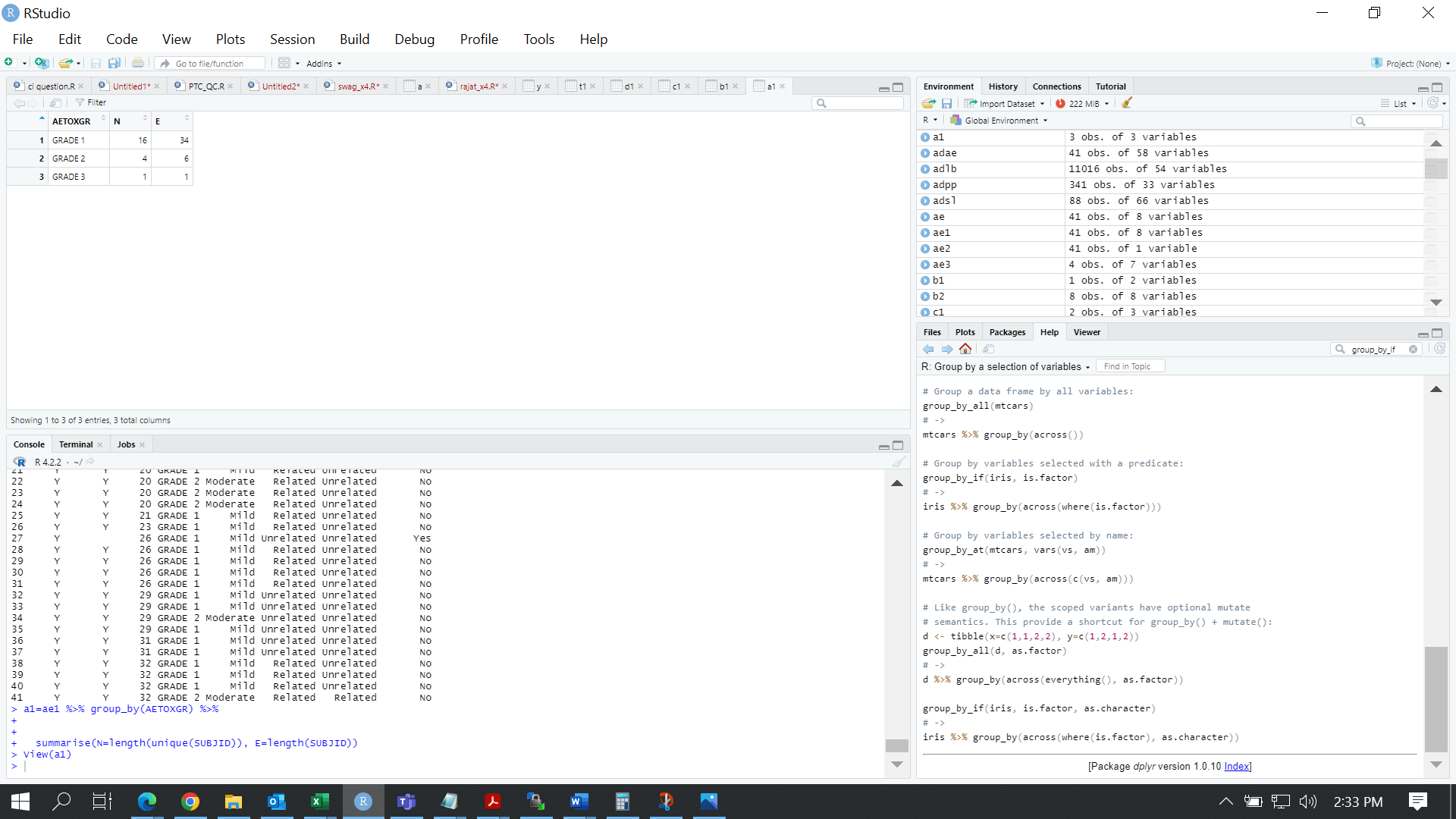
I want to calculate count of unique SUBJID according to severity so that it counts SUBJID only with higher grade severity using group by function of "dplyr" package. so that it will give out of grade 1 is 11 not 16 because grade 2 and grade 3 SUBJID are overlapping with grade 1.
adapt my code example to your own data....
Because of the join; it inherently would maintain your other columns; select is used to have more or less columns.
Your screenshot is not useful to me because I can't access it as a data.frame in R .