I need to get the information from the website www.doctoralia.com.br but I don't know how this is possible.
I loaded the rvest and dplyr libraries and connected the page, but inside the html_nodes() I don't know which attribute I should insert.
I will leave below the link of the doctors of São Paulo.
Can you tell me if it is possible to scrapping this information?
I may have missed it but I don't think you've told us what information from the webpage you want ...
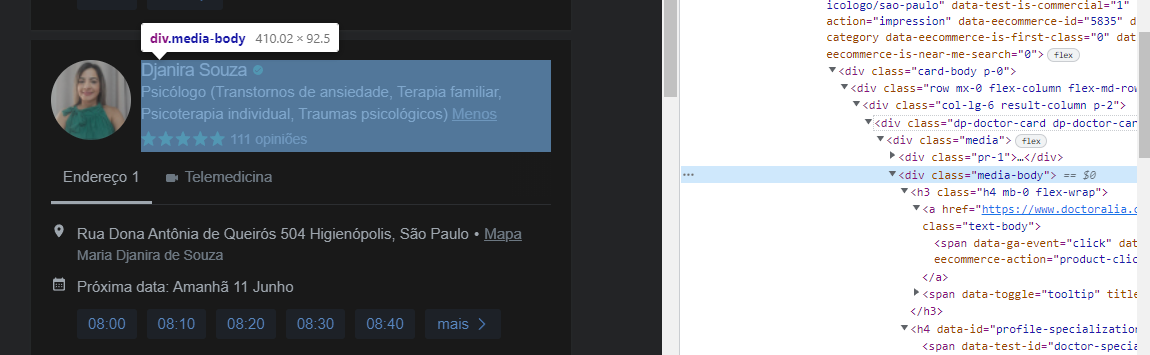
I need to extract all the data from the doctors registered on the site.
Name, Specialty, City, Telephone, Cellular, Address, among others.
I'm not an expert in R. And I've been trying to extract for days but without success.
This article has a lot of information regarding this: Harvesting the web with rvest • rvest
Scraping all of this data might take a bit of effort to gather and then clean, but here is some example code to get the information of the first profile:
library(rvest)
library(dplyr)
URL_test = read_html('https://www.doctoralia.com.br/pesquisa?q=&loc=S%C3%A3o%20Paulo')
CSS_pull2 <-
html_node(URL_test,'.media-body') %>%
html_text()
gsub('\t',' ',gsub('\n', ' ', CSS_pull2))
The following will get you all the nodes for the .media-body element. Again the data is not clean.
CSS_pull = html_nodes(URL_test, '.media-body')
CSS_text = html_text(CSS_pull, trim = TRUE)
gsub('\t',' ',gsub('\n', ' ', CSS_text))
system
July 1, 2022, 7:24pm
5
This topic was automatically closed 21 days after the last reply. New replies are no longer allowed.