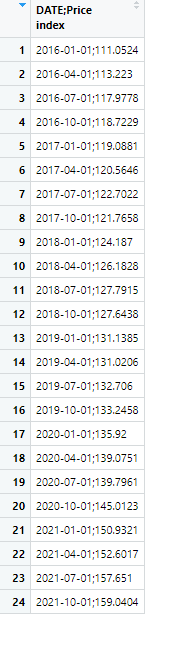
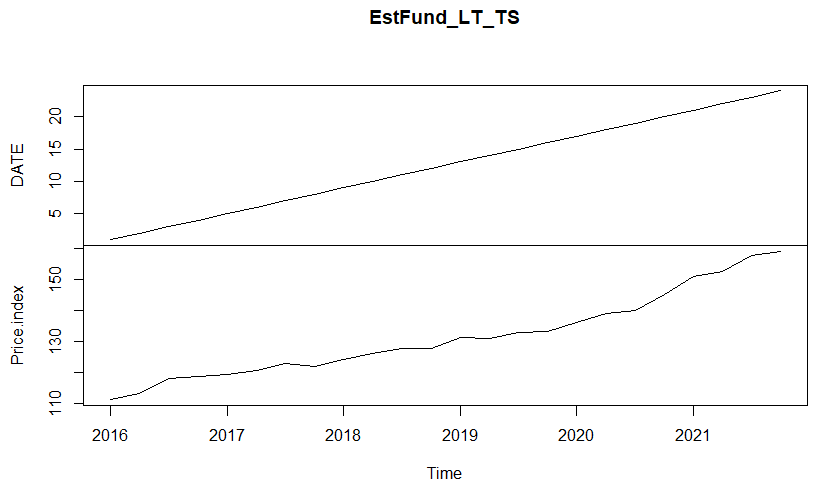
The Problems
There are a few things going on here that are giving you problems:
For context, I am using this as a proxy for your data:
index1 <- data.frame(
'date_price_index' = paste(
seq.Date(
from = as.Date('2016-01-01'),
by = 'quarter',
length.out = 24
),
sapply(
1:24,
function(x) {
returns_range <- seq(
from = -0.001,
to = 0.01,
length.out = 1000
)
111 * (1 + sample(returns_range, size = 1))^x
}
),
sep = ';'
)
)
index1
#> date_price_index
#> 1 2016-01-01;112.006111111111
#> 2 2016-04-01;112.307159184184
#> 3 2016-07-01;113.389950465601
#> 4 2016-10-01;112.425480537166
#> 5 2017-01-01;111.601298700539
#> 6 2017-04-01;116.71557001979
#> 7 2017-07-01;116.362484627963
#> 8 2017-10-01;118.054473986592
#> 9 2018-01-01;110.562767358832
#> 10 2018-04-01;117.562782686146
#> 11 2018-07-01;123.705592755229
#> 12 2018-10-01;115.529226680025
#> 13 2019-01-01;121.544176890339
#> 14 2019-04-01;114.000345177666
#> 15 2019-07-01;111.040006727427
#> 16 2019-10-01;118.818536055432
#> 17 2020-01-01;125.988584972734
#> 18 2020-04-01;113.336921133243
#> 19 2020-07-01;126.138732856221
#> 20 2020-10-01;134.528549634179
#> 21 2021-01-01;113.547430684347
#> 22 2021-04-01;113.64268185571
#> 23 2021-07-01;131.021882107549
#> 24 2021-10-01;124.069172217448
Created on 2022-06-01 by the reprex package (v1.0.0)
First, I am doubtful that you want col_types = c("text") in read_excel. Assuming you are using readxl::read_excel, you probably want either col_types = c('Date', 'double') or, even better yet, just leave that argument out. read_excel will guess the type for you and judging by your data, it will probably be able to guess correctly.
Second, look at what feeding your dataframe to ts ends up creating:
ts(index1, frequency = 4, start = c(2016, 1))
#> Qtr1 Qtr2 Qtr3 Qtr4
#> 2016 1 2 3 4
#> 2017 5 6 7 8
#> 2018 9 10 11 12
#> 2019 13 14 15 16
#> 2020 17 18 19 20
#> 2021 21 22 23 24
That's why your plot ends up looking like a straight line.
The Solution
I would recommend starting with tidyverse tools before getting into base R tools, since base R tools are syntactically more similar to traditional statistical languages, whereas tidyverse tools tend to be closer to natural language.
So to do what you are trying to do with tidy tools, I would do something like this:
# Load tidyr for separating by delimiter
library(tidyr)
library(ggplot2)
library(dplyr)
library(scales)
index1_sep <- index1 %>%
separate(
col = 'date_price_index',
sep = ';',
into = c('date', 'price_index')
) %>%
mutate(
date = as.Date(date),
price_index = as.numeric(price_index)
)
head(index1_sep)
#> date price_index
#> 1 2016-01-01 111.9719
#> 2 2016-04-01 112.1425
#> 3 2016-07-01 111.0557
#> 4 2016-10-01 114.0333
#> 5 2017-01-01 110.5618
#> 6 2017-04-01 114.1397
ggplot(index1_sep, aes(x = date, y = price_index, group = T)) +
geom_line() +
scale_x_date(
date_breaks = '3 months',
label = date_format(format = '%m-%Y')
)