Hi all,
I am trying to run a for loop for the below scenario
- I have 100k Unique customers in my transactional table which are going to n number of stores each customer.
- I am trying to loop through each customer and seeing in which unique store they are going and if new store has opened within 20 kms range to that store then he/she will go to that store and I will make their Value 1 in new data frame created.
- I am initializing my code in first for loop and then repeating the same for rest of my data frame.
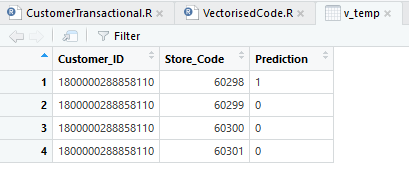
My code is extremely slow with for loop. I don't know how to vectorise my code. Below is the snapshot of my code. Please guide me how to make this code faster and efficient.
EDIT : Added sample dataset now.
cust_id = c(unique(kk$Customer_ID))
i = cust_id[1]
# for initializing
s = c(0,0,0,0)
df_temp = kk[kk$Customer_ID == i]
store = c(unique(df_temp$Store_Code))
for (j in store){
if(df_temp[Store_Code == j]$dist.km298 < 20) {
s[1] <- 1
}
if(df_temp[Store_Code == j]$dist.km299 < 20) {
s[2] <- 1
}
if(df_temp[Store_Code == j]$dist.km300 < 20) {
s[3] <- 1
}
if(df_temp[Store_Code == j]$dist.km301 < 20) {
s[4] <- 1
}
}
vishal <- data.frame("Customer_ID" = c(i,i,i,i) , "Store_Code" = c(60298,60299,60300,60301), "Prediction" = s)
cust_id <- cust_id[!cust_id %in% c(cust_id[1])]
# loop for all customers
count = 1
for (k in 1:length(cust_id)){
i <- cust_id[k]
# count <- count+1
# if (count == 5) {
# break
#}
s = c(0,0,0,0)
df_temp = kk[kk$Customer_ID == i]
store = c(unique(df_temp$Store_Code))
for (j in store){
#if(df_temp$Store_Code == j & df_temp$Purchase_2016 != 0 & df_temp$Purchase_2017 == 0){
if(df_temp[Store_Code == j]$dist.km298 < 20) {
s[1] <- 1
}
if(df_temp[Store_Code == j]$dist.km299 < 20) {
s[2] <- 1
}
if(df_temp[Store_Code == j]$dist.km300 < 20) {
s[3] <- 1
}
if(df_temp[Store_Code == j]$dist.km301 < 20) {
s[4] <- 1
}
}
v_temp <- data.frame("Customer_ID" = c(i,i,i,i) , "Store_Code" = c(60298,60299,60300,60301), "Prediction" = s)
vishal <- rbind.data.frame(vishal,v_temp)
}
dput(head(kk, 5))
structure(list(Customer_ID =
structure(c(1800000006365760, 1800000006365820,1800000006366060
,1800000006366060,1800000006366060), class = "integer64"), Store_Code =
c(60067, 60054, 60066,
60069, 60079), Purchase_2016 = c(2L, 1L, 1L, 1L, 2L), Purchase_2017 =
c(2L,
0L, 0L, 0L, 0L), TotalPurchases = c(4L, 1L, 1L, 1L, 2L), Return_2016 =
c(0L,
0L, 0L, 0L, 0L), Return_2017 = c(0L, 0L, 0L, 0L, 0L), Return_2010 = c(0L,
0L, 0L, 0L, 0L), Rp_Ratio_2016 = c(0, 0, 0, 0, 0), Rp_Ratio_2017 = c(0,
0, 0, 0, 0), Sales_Per_Day = c(1699.6, 2101.1, 1331.4, 1813.1,
1193.1), Store_Launch_Date = structure(c(1323820800, 1322006400,
1338163200, 1311984000, 1385164800), class = c("POSIXct", "POSIXt"
), tzone = "UTC"), Store_Size_Sq_Ft = c(8673.5, 12425.5, 15897.1,
6698.1, 3699.5), Customer_Count = c(89351, 118444, 79249, 114246,
54832), Total_Revenue = c(35350868.4, 43702303, 27693164.7, 37712369.7,
24816886.2), dist.km298 = c(140.24, 123.87, 10.2, 131.96, 128.52
), dist.km299 = c(163.37, 140.2, 79.32, 153.01, 145.03), dist.km300 =
c(4.09,
21.05, 126.55, 7.03, 17.41), dist.km301 = c(5.72, 19.04, 125.46,
5.02, 15.4), Nationality = c("INDIA", "UNITED ARAB EMIRATES",
"SRI LANKA", "SRI LANKA", "SRI LANKA"), Gender = c("M", "F",
"M", "M", "M"), Marital_Status = c("Married", "Married", "Married",
"Married", "Married"), Loyalty_Status = c("Gold", "Silver", "Silver",
"Silver", "Silver"), Points = c(814L, 212L, 186L, 186L, 186L),
Age = c(59L, 119L, 59L, 59L, 59L), LastVisit = c(2, 28, 3,
3, 3), Last_rdm_txn_dt1 = structure(c(17601, 16510, 17196,
17196, 17196), class = "Date"), Last_accr_txn_dt1 = structure(c(17801,
17029, 17774, 17774, 17774), class = "Date")), .Names = c("Customer_ID",
"Store_Code", "Purchase_2016", "Purchase_2017", "TotalPurchases",
"Return_2016", "Return_2017", "Return_2010", "Rp_Ratio_2016",
"Rp_Ratio_2017", "Sales_Per_Day", "Store_Launch_Date",
"Store_Size_Sq_Ft",
"Customer_Count", "Total_Revenue", "dist.km298", "dist.km299",
"dist.km300", "dist.km301", "Nationality", "Gender", "Marital_Status",
"Loyalty_Status", "Points", "Age", "LastVisit", "Last_rdm_txn_dt1",
"Last_accr_txn_dt1"), sorted = "Customer_ID", class = c("data.table",
"data.frame"), row.names = c(NA, -5L), .internal.selfref = <pointer:
0x0000000004810788>)
This is my final output required