i' m confronted with an issue and i hope someone can help me out. I'm creating an own dataset, which includes data about competency Models (Release, Name, Version, etc). I want my dataset to be tidy according to Wickham's definition. My issue is the following:
To me, i think the observation unit is the Competency Model. However if this is the case, this dataset is not tidy, because the observation is scattered accros rows and to my knowledge this violates the tidy data structure. This happens, because there is not one kind of user, there are several. How can i fix this Problem? If you have an idea, please let me know =)
PS: I'm not interessted in how this might problem might be coded, i 'm !just interessted in how this data set might be looking in tidy data structure.
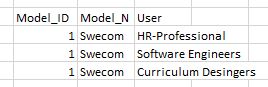
This is my simple data set, i'm not able to tidy =(
I think we would need more context to give you better advice but from what I can see the observation unit would be "the use" of competency models, in which case the dataset would be tidy.
Thank you for your reply. I'm collecting meta-data and data about competency models for IT Security/CyberSecurity, data about their application/uses, where (Country) those models are used and so on, in order to analyse them. In the data set i collected data about the model and its users.Every Competency model has its intended audience and i want to refelct this in my hopefully tidy data set.
So i thought, maybe there are two observation units "attributes of competency model" and "use of competency model", then this would lead to the following table:
and in the old table i would remove the variable user.
However, if i do this, than i wonder whats the observational unit? The "use" of the competency models, as you suggested?
To clarify a little bit my previous comment, I think a relational database would be the better to contain and structure your data but for representation purposes you can query the database as tidy dataframes as needed.
Thank you very much. Some somewhat naive questions: In order to maintain the relational database, i would use mySQL or something, right? But, R does not understand relational tables, right? Do you recommend this approach, because i have multiple observation, which are linked to each other?
One claryfing question: you said the observation unit would be "the use" of competency model. Can you clarify, why each rows i a single observation and not one observation scattered around multiple rows?
Yes, you would need some sql engine, for sporadic and simple use, I would go with SQLite or similar and for more heavy use PostgreSQL
You can interact with almost any database from R (using specialized packages) and even more you can manipulate data on the sql server from R using dplyr like syntax with dbplyr. This approach has the advantage of moving the actual data processing to the SQL server enabling you to work with larger than memory datsets.
I recommend this to avoid redundancy since I think you have different kinds of data for the same entity.
Sorry if this is not clear enough but my theoreticall knowledge of relational databases is a bit rusty and I can't remember the technical terms to use.