Hello, I'm still a novice to R. Can anyone help me figure out how to spread my dataset under different categories?
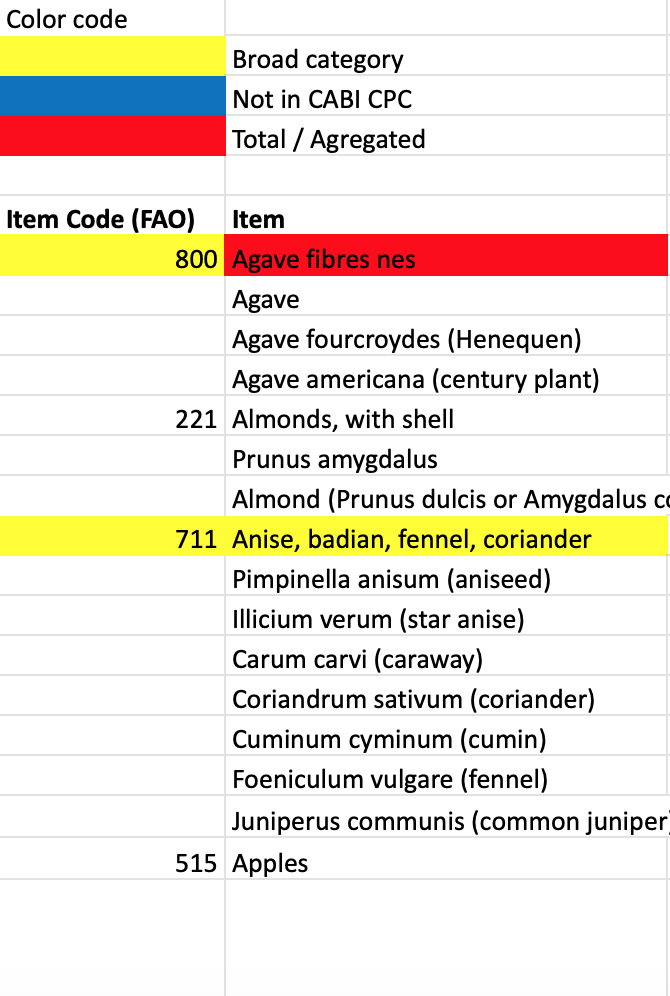
The following is the dataset description: items with item code are my broad categories, and others without code fall in the subcategories. I want to make my broad items together with codes in two separate columns, and associated subcategories (I mean items under the broad categories)in another column. (Like column#1 is "Item Code", column#2 is "Broad category", and column #3 is " Specific items")
Can anyone tell me how to do this? I'm trying to use spread( ) command, but I think it doesn't work, because in that way I will get a new table which is super "wide".
Hello! Thanks for your reply.
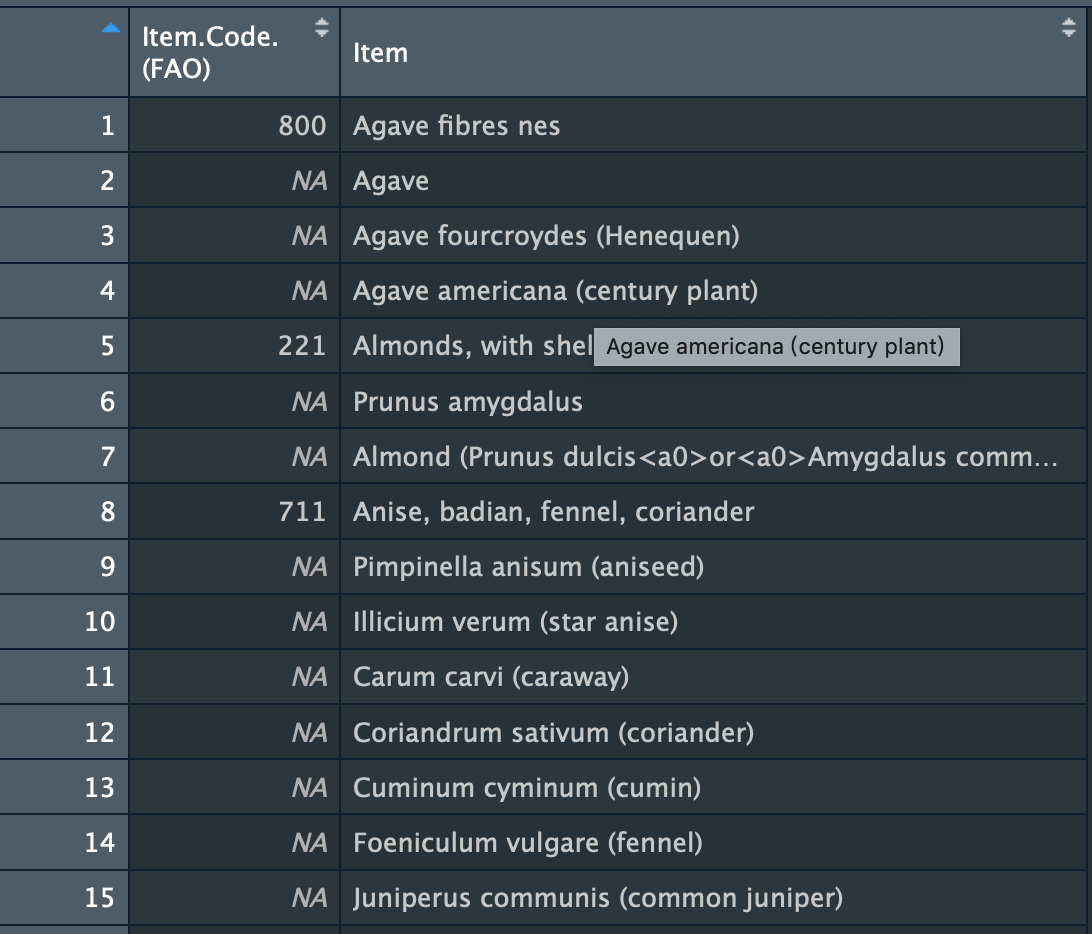
I haven't imported my dataset into R yet, I'm just thinking about my following steps and how to separate the original "Item" column into two. I had experience in doing spread() command, but in this case, it seems doesn't work. Do you know how to put all the "broad category" into one column, and the other items in another column? Just like this (I mean after I do some sorting work in R):
It can depend on what happens when you import the file since that may change what the table looks like once it's in R. Could you import it and paste what you get here?
As I described, values with "item code" fall in "broad category", others are in the subcategories. So now, I wanna separate values in subcategories (that is, values with NA code) and make it into the third column. And I wish the final result could be like the form in my last reply.
Can I specify "broad categories" as a variable, and "subcategories" as another variable, and then, I might be able to spread the table? Not sure.
Great! The next step is to get your table in shape so that folks who want to help can copy and paste into their own R files. One way to start is to copy the code you used to import the table, and paste it here between a pair of triple backticks (```), like this:
```
<--- paste your code here
```
and then do the same with the output you get from applying the function dput() to the name of your table:
```
<--- paste output of dput(your_table) here
```
That will make it easier to make sure folks can recreate your situation and help you more effectively.
Ideally, you should provide a reproducible example for your issue, you can learn how to make one by reading this FAQ
Since you are new to R, I'm going to give you an example with some made-up data, this is an extra effort for people trying to help you so next time, please read the guide and try to provide a proper reprex.
library(tidyverse)
sample_df <- data.frame(
stringsAsFactors = FALSE,
item_code = c(100, NA, NA, NA, 200, NA, NA, NA),
item = c("A", "a1", "a2", "a3", "B", "b1", "b2", "b3")
)
sample_df
#> item_code item
#> 1 100 A
#> 2 NA a1
#> 3 NA a2
#> 4 NA a3
#> 5 200 B
#> 6 NA b1
#> 7 NA b2
#> 8 NA b3
sample_df %>%
mutate(item_code = ifelse(!is.na(item_code), item, item_code)) %>%
fill(item_code, .direction = "down") %>%
filter(item_code != item)
#> item_code item
#> 1 A a1
#> 2 A a2
#> 3 A a3
#> 4 B b1
#> 5 B b2
#> 6 B b3
Created on 2020-03-14 by the reprex package (v0.3.0.9001)
If you run the command dput(crop.sorted), you'll see its output in your RStudio console, which is in the lower left pane. That output is what you want copy and paste here, whereas you pasted the command itself. Could you do that?
Perfect! Thank you so much, it works!
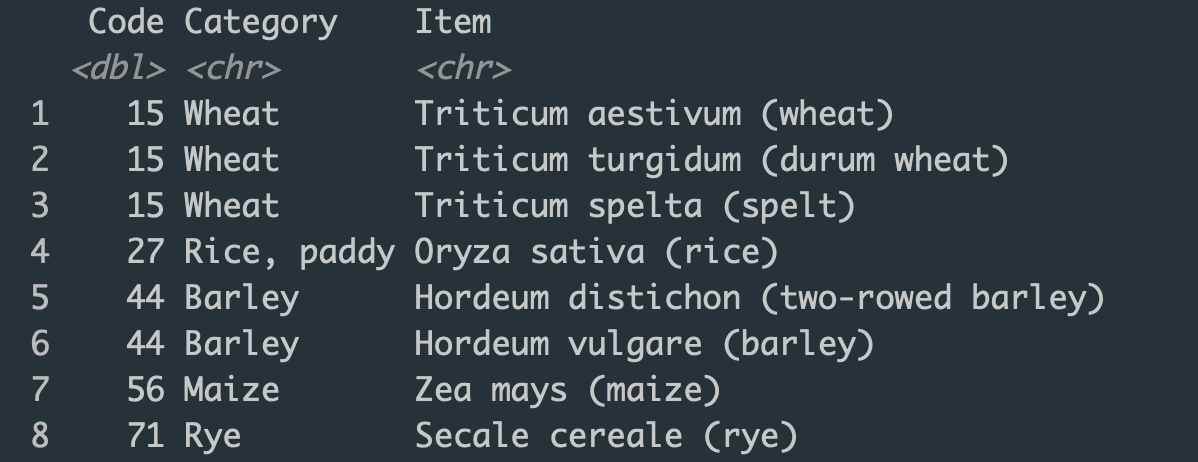
Based on your code, I also found an alternative way, which allows keeping item code while getting the "broad category" and "subcategories".
Here is what I got: