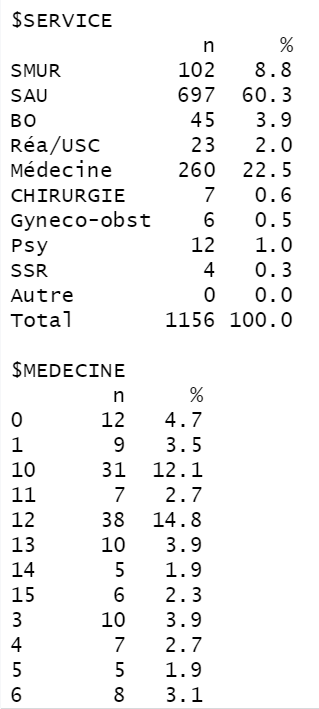
Hi I am in internship now. One of my goals is to describe variables.I have describe numbers and frequencies for the qualitative variables. I put all of my variables of interest in a list named var.quali and and used lapply to compute their frequencies and numbers with the function Frequences(which I computed myself)
I compute the function Frequences so that so that the NA values would not be took account
Assuming that's a list of data frames, if you've got the same variables for each element in the list, I'd condense the list into a single data frame, e.g.
Thanks Alistaire the script works well. It has been as I want, except I would like to have the total at the last row not on the the top (even though it is the greatest value), like are usually presented the results of scientific articles. I was wondering if it was possible to do a conditional sorting without touching the row of totals.
Thank you anyway!
It's possible if you make an extra column with whether a row is a total or not (... %>% mutate(is_total = value == "Total") and use that as an additional variable to sort by (... %>% arrange(..., is_total)).
That said, I'd recommend dropping the total rows or separating them into a second data frame (which you should be able to recreate from the granular data; with dplyr, df %>% group_by(...) %>% summarise_all(sum) or similar). That arrangement will ultimately be more useful for a lot of operations beyond sorting.