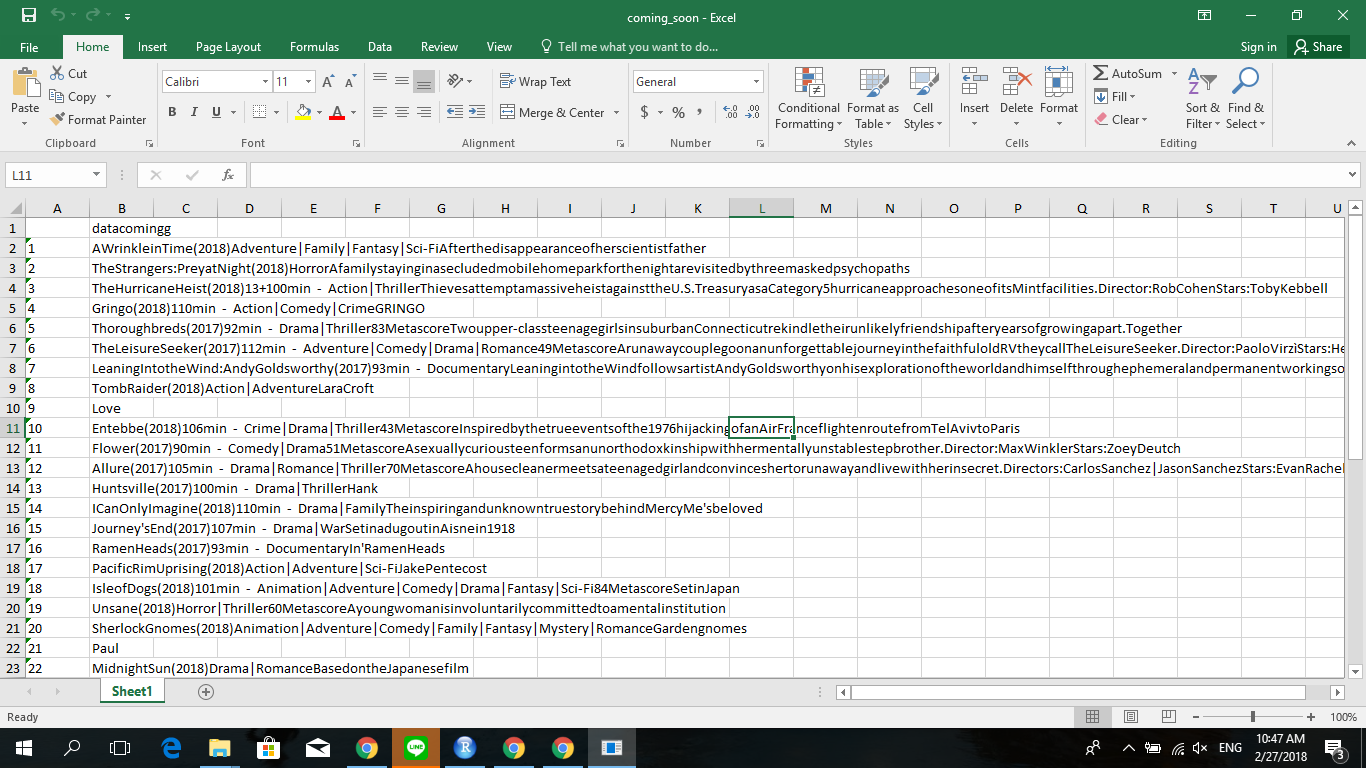
You can use rvest and tidyverse tools to create the table you want directly in R before exporting it in a file.
Use css selectors to get exactly the item you want from the page. Developer’s tool on a navigator (F12) or SelectorGadget can help you.
Here is how you can create a table with the useful information
library(tidyverse)
# not in the core tidyverse
library(rvest)
#> Le chargement a nécessité le package : xml2
#>
#> Attachement du package : 'rvest'
#> The following object is masked from 'package:purrr':
#>
#> pluck
#> The following object is masked from 'package:readr':
#>
#> guess_encoding
url = "https://www.imdb.com/movies-coming-soon/?ref_=nv_mv_cs_4"
# get list of film coming soon
coming_soon <- url %>%
read_html() %>%
html_nodes(".list_item")
# create a table to contain information: one line per film
coming_movies <- tibble::tibble(
# get the title (unique)
title = coming_soon %>%
html_node(".overview-top h4[itemprop='name'] a") %>%
html_text() %>%
str_trim(),
# get the genre (several per film)
genre = coming_soon %>%
# use purrr::map to get one list per film (otherwise html_nodes gets you a vector too big)
map(~ html_nodes(.x, ".cert-runtime-genre span[itemprop='genre']") %>%
html_text()),
# get time in min of the film if any
time_in_min = coming_soon %>%
html_node("time") %>%
html_text() %>%
# parse the number
parse_number() %>%
as.integer(),
# get the description (unique)
description = coming_soon %>%
html_node(".outline[itemprop='description']") %>%
html_text() %>%
# trim whitespace and newlines on both sides
str_trim(),
# get the directors (several possible per film)
director = coming_soon %>%
map(~ html_nodes(.x, ".txt-block span[itemprop='director'] span[itemprop='name'] a") %>% html_text()),
# get the starring actos (several possible per film)
stars = coming_soon %>%
map(~ html_nodes(.x, ".txt-block span[itemprop='actors'] span[itemprop='name'] a") %>% html_text())
) %>%
# extract year from the title
mutate(
year = str_extract(title, "\\(\\d{4}\\)") %>%str_remove_all("[\\(\\)]"),
title = str_remove(title, "\\(\\d{4}\\)$") %>% str_trim()
)
coming_movies
#> # A tibble: 41 x 7
#> title genre time_in_min description director stars year
#> <chr> <list> <int> <chr> <list> <lis> <chr>
#> 1 Un Rac~ <chr ~ NA After the disappearanc~ <chr [1~ <chr~ 2018
#> 2 The St~ <chr ~ NA A family staying in a ~ <chr [1~ <chr~ 2018
#> 3 Hurric~ <chr ~ 100 Thieves attempt a mass~ <chr [1~ <chr~ 2018
#> 4 Gringo <chr ~ 110 GRINGO, a dark comedy ~ <chr [1~ <chr~ 2018
#> 5 Thorou~ <chr ~ 92 Two upper-class teenag~ <chr [1~ <chr~ 2017
#> 6 L'écha~ <chr ~ 112 A runaway couple go on~ <chr [1~ <chr~ 2017
#> 7 Leanin~ <chr ~ 93 Leaning into the Wind ~ <chr [1~ <chr~ 2017
#> 8 Tomb R~ <chr ~ NA Lara Croft, the fierce~ <chr [1~ <chr~ 2018
#> 9 Love, ~ <chr ~ 109 Everyone deserves a gr~ <chr [1~ <chr~ 2018
#> 10 Entebbe <chr ~ 106 Inspired by the true e~ <chr [1~ <chr~ 2018
#> # ... with 31 more rows
You’ll get a table with some list column containing charater vectors. You can either
manipulate in R list columns with purrr helping
unnest the table as necessary (but all list column are not the same length),
paste the characters together
# exemple for choice 2
coming_movies %>%
modify_if(is.list, ~ map_chr(.x, paste, collapse = ","))
#> # A tibble: 41 x 7
#> title genre time_in_min description director stars year
#> <chr> <chr> <int> <chr> <chr> <chr> <chr>
#> 1 Un Rac~ Advent~ NA After the disappear~ Ava DuV~ Gugu M~ 2018
#> 2 The St~ Horror NA A family staying in~ Johanne~ Christ~ 2018
#> 3 Hurric~ Action~ 100 Thieves attempt a m~ Rob Coh~ Toby K~ 2018
#> 4 Gringo Action~ 110 GRINGO, a dark come~ Nash Ed~ Joel E~ 2018
#> 5 Thorou~ Drama,~ 92 Two upper-class tee~ Cory Fi~ Anya T~ 2017
#> 6 L'écha~ Advent~ 112 A runaway couple go~ Paolo V~ Helen ~ 2017
#> 7 Leanin~ Docume~ 93 Leaning into the Wi~ Thomas ~ Andy G~ 2017
#> 8 Tomb R~ Action~ NA Lara Croft, the fie~ Roar Ut~ Alicia~ 2018
#> 9 Love, ~ Comedy~ 109 Everyone deserves a~ Greg Be~ Nick R~ 2018
#> 10 Entebbe Crime,~ 106 Inspired by the tru~ José Pa~ Daniel~ 2018
#> # ... with 31 more rows
Hope this example helps
Created on 2018-02-27 by the reprex package (v0.2.0).
library(tidyverse)
library(rvest)
library(reprex)
library(stringr)
url = "https://www.imdb.com/movies-coming-soon/?ref_=nv_mv_cs_4"
# get list of film coming soon
coming_soon <- url %>%
read_html() %>%
html_nodes(".list_item")
# create a table to contain information: one line per film
coming_movies <- tibble::tibble(
# get the title (unique)
title = coming_soon %>%
html_node(".overview-top h4[itemprop='name'] a") %>%
html_text() %>%
str_trim(),
# get the genre (several per film)
genre = coming_soon %>%
# use purrr::map to get one list per film (otherwise html_nodes gets you a vector too big)
map(~ html_nodes(.x, ".cert-runtime-genre span[itemprop='genre']") %>%
html_text()),
# get time in min of the film if any
time_in_min = coming_soon %>%
html_node("time") %>%
html_text() %>%
# parse the number
parse_number() %>%
as.integer(),
# get the description (unique)
description = coming_soon %>%
html_node(".outline[itemprop='description']") %>%
html_text() %>%
# trim whitespace and newlines on both sides
str_trim(),
# get the directors (several possible per film)
director = coming_soon %>%
map(~ html_nodes(.x, ".txt-block span[itemprop='director'] span[itemprop='name'] a") %>% html_text()),
# get the starring actos (several possible per film)
stars = coming_soon %>%
map(~ html_nodes(.x, ".txt-block span[itemprop='actors'] span[itemprop='name'] a") %>% html_text())) %>%
# extract year from the title
mutate(
year = str_extract(title, "\\(\\d{4}\\)") %>%str_remove_all("[\\(\\)]"),
title = str_remove(title, "\\(\\d{4}\\)$") %>% str_trim()
)
and still error, and this error is
Error in mutate_impl(.data, dots) :
Evaluation error: could not find function "str_remove_all".
Error: object 'coming_movies' not found
thank you for help me sir, and please help me again for my understanding
As mentionned earlier, have you installed stringr version 1.3.0 ? Can you check what version you have ? Thanks.
If you have stringr < 1.3.0, it won't work. So, if you can't or don't want to update, just replace the last mutate
mutate(
year = str_extract(title, “\(\d{4}\)”) %>%str_remove_all("[\(\)]"),
title = str_remove(title, “\(\d{4}\)$”) %>% str_trim()
)
by this one
mutate(
year = str_extract(title, "\\(\\d{4}\\)") %>%str_replace_all("[\\(\\)]", ""),
title = str_replace(title, "\\(\\d{4}\\)$", "") %>% str_trim()
)
Is this ok for you ?
Some comments about posting here and helping us help you:
Try to take care of the style of your code. Currently, your last answer is unreadable and not useful because code is not highlited properly.
In the answer box edition, you can select some text an click on this button to transform the block to code syntax:
You can check what you do in the preview on the left.
Also,
Take a look at the markdown syntax, that you could use in a post: Markdown Reference