Some web links do not load whole page until we scroll down (eg: http://www.espncricinfo.com/series/13062/commentary/428753/australia-vs-england-5th-test-england-tour-of-australia-2010-11?innings=1). I need to scrape commentary lines from web link using RStudio. If I try to scrape data using web scraping from links, it copies only data which load first few lines but not the whole page.
I tried this,
library(rvest)
url = "http://www.espncricinfo.com/series/13062/commentary/428753/australia-vs-england-5th-test-england-tour-of-australia-2010-11?innings=1"
page = read_html(url)
pagehtml = html_nodes(page, '.description')
htmltext(pagehtml )
Hi @Kusal95,
To solve your problem I would look at RSelenium. This will allow you to interact with the webpage which is not currently possible within rvest. This StackOverflow question goes over using RSelenium with infinite scroll (your current situation) and should be able to assist you further.
1 Like
Thank you for your advice....
This gives an error
#start RSelenium
checkForServer()
startServer()
remDr <- remoteDriver()
remDr$open()
---error--
[1] "Connecting to remote server"
Error in checkError(res) :
Undefined error in httr call. httr output: Failed to connect to localhost port 4445: Connection refused
I checked it out and all you need to do after you read the page is get div class = content:
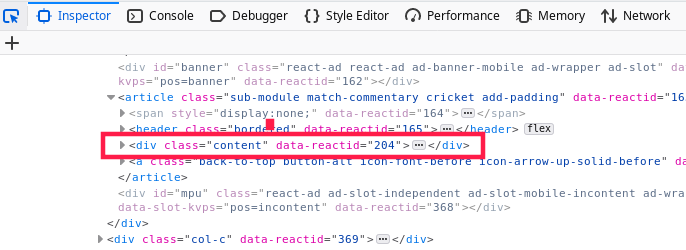
Once you do that, everything else will be easy. I would recommend BeautifulSoup.
Another challenge is getting connected to the webserver, That is where requests library excels.
I love R, but when it comes to networking and webscraping I use Python. You can even evade detection.
Good luck
thank you. I will try it...
This topic was automatically closed 21 days after the last reply. New replies are no longer allowed.