Yes, the group_by() causes the calculation of summarize() to be done on the unique combinations of Question, Sex, and Age Group. The .groups argument of summarize() controls how the output of summarize is grouped. The Help of summarize explains the various options. It does not affect the calculated values of summarize, only how the tibble is grouped.
Here is a start on reversing the original pivot_longer. You have to reverse the coding from numbers to text. I ignored the division by n(). Since there is only one member in each group, it does not make a difference. If there were multiple members, you would have to store the value of n(), since it cannot be determined from the summarized data.
library(tidyverse)
df <- structure(list(Sex = c(1L, 2L, 1L, 2L), `Age Group` = structure(c(1L,
1L, 2L, 2L), .Label = c("30-39", "40-49"), class = "factor"),
Q31 = c(1L, 3L, 4L, 2L), Q32 = c(7L, 5L, 6L, 2L), Q33 = 1:4,
Q34 = c(5L, 6L, 2L, 2L)), class = "data.frame", row.names = c(NA,
-4L))
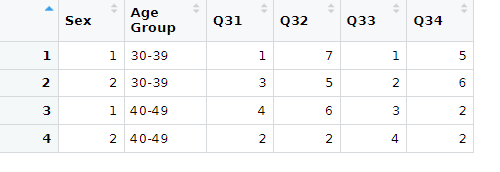
df
#> Sex Age Group Q31 Q32 Q33 Q34
#> 1 1 30-39 1 7 1 5
#> 2 2 30-39 3 5 2 6
#> 3 1 40-49 4 6 3 2
#> 4 2 40-49 2 2 4 2
df1 <- df %>%
pivot_longer(cols = -c(Sex, `Age Group`),
names_to = "Question",
values_to = "Value") %>%
group_by(Question, Sex, `Age Group`) %>%
summarise(`Strongly Agree` = sum(Value == 7)/n(),
`Slightly Agree` = sum(Value == 6)/n(),
Agree = sum(Value == 5)/n(),
Neutral = sum(Value == 4)/n(),
Disagree = sum(Value == 3)/n(),
`Slightly Disagree` = sum(Value == 2)/n(),
`Strongly Disagree` = sum(Value == 1)/n())
#> `summarise()` has grouped output by 'Question', 'Sex'. You can override using
#> the `.groups` argument.
df1 |> pivot_longer(cols = -c("Question","Sex","Age Group"),
names_to = "Category", values_to = "Value") |>
filter(Value > 0) |>
mutate(Score = case_when(
Category == "Strongly Agree" ~ 7,
Category == "Slightly Agree" ~ 6,
Category == "Agree" ~ 5,
Category == "Neutral" ~ 4,
Category == "Disagree" ~ 3,
Category == "Slightly Disagree" ~ 2,
Category == "Strongly Disagree" ~ 1
)) |>
select(-Category, -Value) |>
pivot_wider(names_from = "Question", values_from = "Score") |>
arrange(`Age Group`, Sex)
#> # A tibble: 4 × 6
#> # Groups: Sex [2]
#> Sex `Age Group` Q31 Q32 Q33 Q34
#> <int> <fct> <dbl> <dbl> <dbl> <dbl>
#> 1 1 30-39 1 7 1 5
#> 2 2 30-39 3 5 2 6
#> 3 1 40-49 4 6 3 2
#> 4 2 40-49 2 2 4 2
Created on 2022-12-24 with reprex v2.0.2