The sparklyr R code is as below. JSON file is successfully read and nested columns are invoked. But in nested columns, there are many repeated column names. In following code, I want to rename 'hashtags' column name.
sc <- spark_connect(master = "local", config = conf, version = '2.2.0')
sample_tbl <- spark_read_json(sc,name="example",path="example.json", header = TRUE, memory = FALSE, overwrite = TRUE)
sdf_schema_viewer(sample_tbl) # to create db schema
df <- spark_dataframe(sample_tbl)
parsedCol = list(
invoke(df,"col","created_at"),
invoke(df,"col","entities.hashtags"),
invoke(df,"col","entities.media.additional_media_info.description"),
invoke(df,"col","entities.media.additional_media_info.embeddable"),
invoke(df,"col","entities.media.additional_media_info.monetizable")
)
out = df %>% invoke("select", parsedCol)
sdf_register(out,"parsedSample_tbl")
Any solution would be appreciated.
Why not use dplyr? As in...
library(sparklyr)
library(dplyr)
sc <- spark_connect(master = "local", config = conf, version = '2.2.0')
sample_tbl <- spark_read_json(sc,name="example",path="example.json", header = TRUE, memory = FALSE, overwrite = TRUE)
sample_tbl %>% rename(renamed_hashtag = entities.hashtags)
@javierluraschi,
sample_tbl %>% rename(renamed_hashtag = entities.hashtags)
It gives error. It does not rename for deep 2nd,3rd,4th level nested column names. It only renames for first level column. [Please refer database schema given in 2nd reply]
Error :
Error in .f(.x[[i]], ...) : object 'entities.hashtags' not found
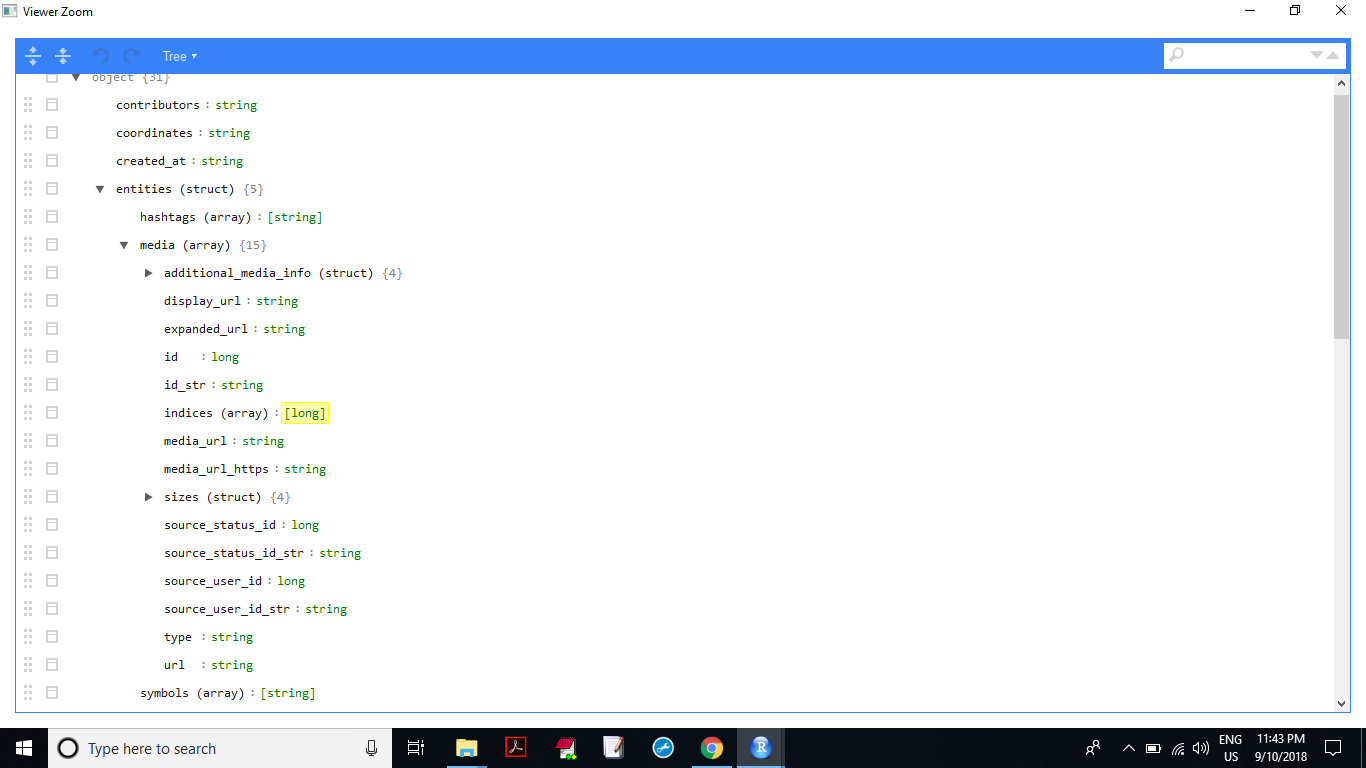
@javierluraschi, My Database schema is as below,
Try using DBI::dbGetQuery() to select the fields you need, here is an example that you should be able to adapt to your use case:
writeLines('[{"a":1,"b":{"a":10,"b":100}},{"a":2,"b":{"a":20,"b":200}}]', "test.json")
library(sparklyr)
sc <- spark_connect(master = "local")
spark_read_json(sc, "nested", "test.json")
DBI::dbGetQuery(sc, "SELECT b.a FROM nested")
a
1 10
2 20
I'm not 100% sure this is unsupported in dplyr, but opened https://github.com/tidyverse/dbplyr/issues/158 to continue this investigation.
@javierluraschi, I have tried this also. But it gives very big error.