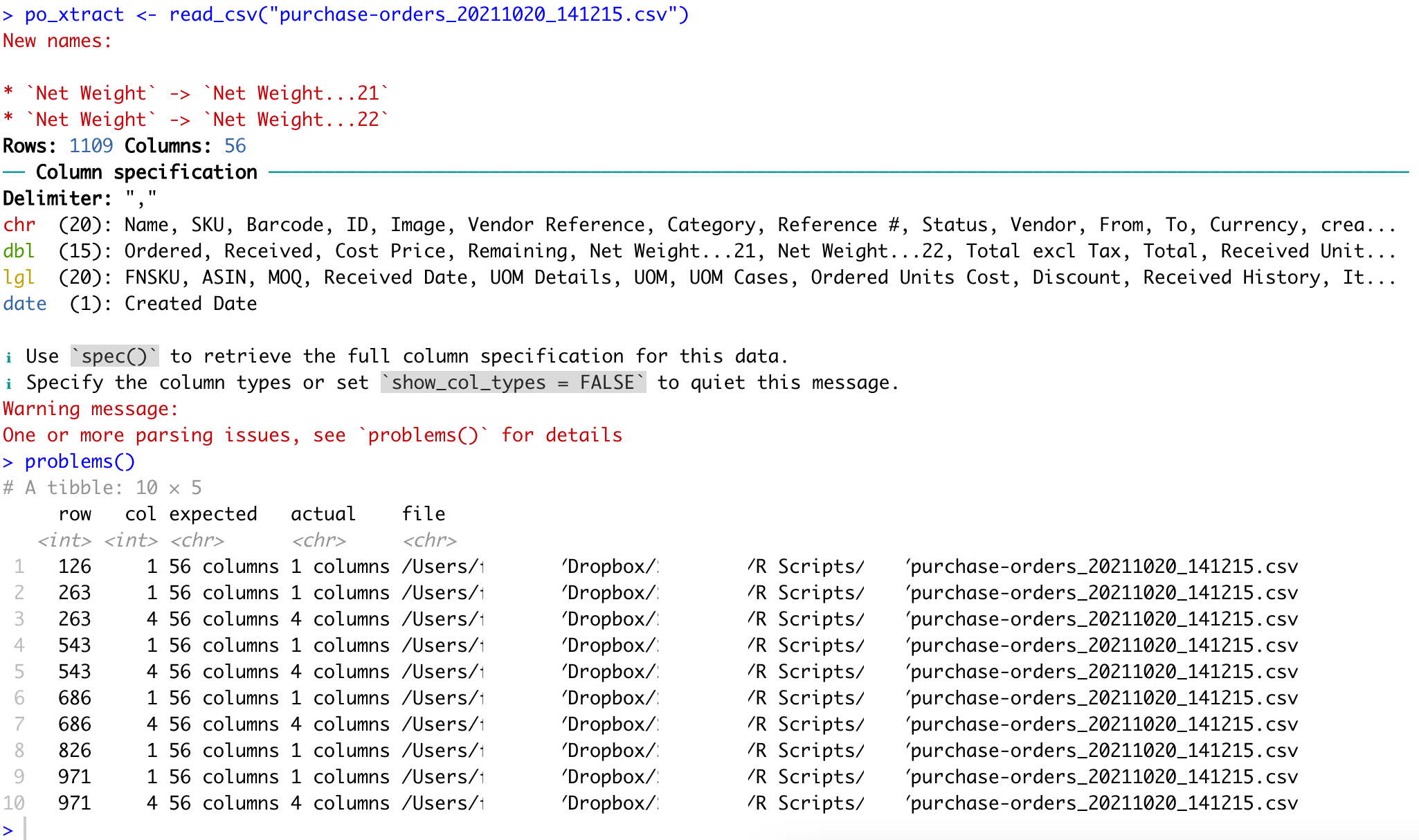
the problem() listings tell you the rows of the file read in on which there were issues , not the rows in the resulting df post readin. i.e. if row 1 is the header that doesnt get a row in your data.frame; you should slice(125)
I had a problem with a file and discovered many of the entries had commas within the columns. I used Excel's find and replace to change the commas to semi-colons (I think there were over 87,000 commas). That solved my problem.
Thank you for that information! I did check it again but didn't see anything out of the ordinary compared to the other rows. I wish I can recreate the problem using another dataset so I can show you guys.
Thanks for the help technocrat! I wish I can recreate the problem using another dataset so I can show you. I didn't see anything out of the ordinary compared to the other rows. All information were loaded completely anyway.
Try bringing in the first half only. If a problem, the first quarter. Then the first eighth. If necessary go on to the second half. The missing comma problem is hard to see, especially if you have quotation marks in the file. BTW: this is called a "quartering search."