I am trying to get href from every tags "a"
xml2::read_html("World Population Prospects - Population Division - United Nations")
I am trying to get href from every tags "a"
xml2::read_html("World Population Prospects - Population Division - United Nations")
I think that this page is generated with java script and therefore needs a technique such as Selenium.
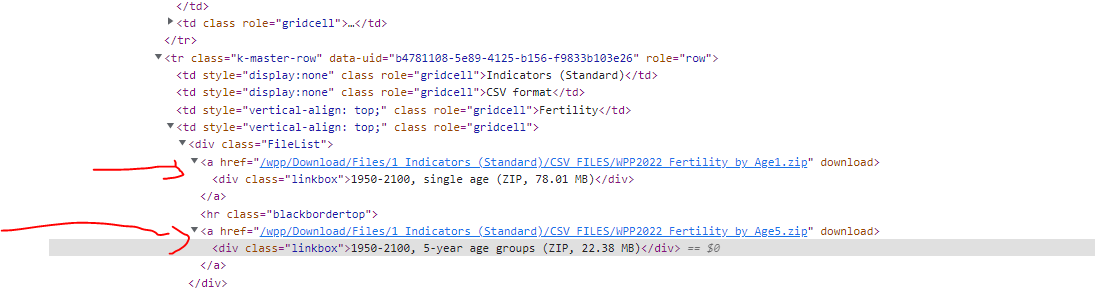
Below two solutions without and with RSelenium.
Only the latter solution shows the urls that you marked in red.
suppressPackageStartupMessages(
{
library(xml2)
library(purrr)
library(RSelenium)
}
)
url <- "https://population.un.org/wpp/Download/Standard/CSV/"
# without RSelenium
doc1 <- read_html(url)
x1a <- xml_find_all(doc1,"//div['FileList']/a")
x1b <- purrr::map_chr(x1a,~xml_attr(.,"href"))
head(x1b)
# with RSelenium
rD <- rsDriver(browser = 'firefox',port=4567L,verbose=F)
remDr <- rD[["client"]]
remDr$navigate(url)
doc2 = xml2::read_html(remDr$getPageSource()[[1]])
x2a <- xml_find_all(doc2,"//div['FileList']/a")
x2b <- purrr::map_chr(x2a,~xml_attr(.,"href"))
head(x2b)
remDr$close()
rD[["server"]]$stop()
rm(rD)
Thanks for explaining (webpage is created by java)
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.
If you have a query related to it or one of the replies, start a new topic and refer back with a link.