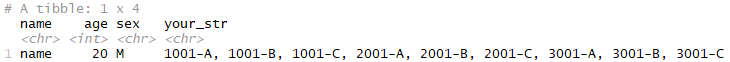Json structure looks like below
{name: name,
age: 20,
sex: M,
clasification: {
category: [ {id: 1001, loc:[A, B, C] },
subcategory: [ {id: 2001, loc:[A, B, C] },
type: [ {id: 3001, loc:[A, B, C] }
}
Json structure looks like below
{name: name,
age: 20,
sex: M,
clasification: {
category: [ {id: 1001, loc:[A, B, C] },
subcategory: [ {id: 2001, loc:[A, B, C] },
type: [ {id: 3001, loc:[A, B, C] }
}
Your JSON looks malformed. Strings should be quoted:
RFC 4627 - The application/json Media Type for JavaScript Object Notation (JSON)
2.2. Objects
An object structure is represented as a pair of curly brackets surrounding zero or more name/value pairs (or members). A name is a string. A single colon comes after each name, separating the name from the value. A single comma separates a value from a following name. The names within an object SHOULD be unique.
object = begin-object [ member *( value-separator member ) ]
end-objectmember = string name-separator value
[...]
2.5. Strings
The representation of strings is similar to conventions used in the C family of programming languages. A string begins and ends with quotation marks. [...]
Once you get well formed JSON, you should look at the rjson package and see if that helps:
jsonlite is another option to read in json once you deal with the formatting issues.
thanks for your fast reply..
i do understand the json std is wrong.
i just added that to make understand the format.
i tried jsonlite, i got the same object as same as mongolite..
thanks
mongolite uses jsonlite internally. Moreover, both packages are written by the same person, so it's not surprising you got the same result.
@pillai, do you have an example of correctly formatted JSON, perhaps in the format of an R character string? I'm sure members of the RStudio Community would be happy to help if provided with a reproducible example.
Assuming the JSON is supposed to be this...
{
"name": "hisName",
"age": "20",
"sex": "M",
"classification": {
"category": [{
"id": 1001,
"loc": ["A1", "B1", "C1"]
}],
"subcategory": [{
"id": 2001,
"loc": ["A2", "B2", "C2"]
}],
"type": [{
"id": 3001,
"loc": ["A3", "B3", "C3"]
}]
}
}
... you can use rjson thusly...
> library(rjson)
> json_data <- fromJSON(myJson)
> json_data
$name
[1] "hisName"
$age
[1] "20"
$sex
[1] "M"
$classification
$classification$category
$classification$category[[1]]
$classification$category[[1]]$id
[1] 1001
$classification$category[[1]]$loc
[1] "A1" "B1" "C1"
$classification$subcategory
$classification$subcategory[[1]]
$classification$subcategory[[1]]$id
[1] 2001
$classification$subcategory[[1]]$loc
[1] "A2" "B2" "C2"
$classification$type
$classification$type[[1]]
$classification$type[[1]]$id
[1] 3001
$classification$type[[1]]$loc
[1] "A3" "B3" "C3"
I'm going to take a stab at this although I'm going to have to assume a couple things.
name, age, sex, category, subcategory and type. Where category, subcategory and type are all nested dataframes containing the variables id and loc. (Note: the values in id will be duplicated the same number of times as the length of loc (3), so it fits in a dataframe.classification can actually be removed as seems to add an unneeded level to the structure.I didn't feel like writing out the JSON as a character string so I created a list mimicking the structure of your proposed JSON.
your_list <- list(
name = "name",
age = 20,
sex = "M",
classification = list(
category = list(
id = 1001,
loc = c("A", "B", "C")
),
subcategory = list(
id = 2001,
loc = c("A", "B", "C")
),
type = list(
id = 3001,
loc = c("A", "B", "C")
)
)
)
As @mishabalyasin suggested, jsonlite is a well-rounded package that can convert both to and from JSON. We'll convert the above object your_list to a JSON object, and then coerce it back into a list, this is done with jsonlite::toJSON() and jsonlite::fromJSON(). After this, we'll go ahead and reshape this list so it becomes a nested dataframe with one row, following the assumptions I've mentioned above.
library(jsonlite)
library(tidyverse)
your_df <- your_list %>%
# make json, then make list
toJSON() %>%
fromJSON() %>%
# remove classification level
purrr::flatten() %>%
# turn nested lists into dataframes
map_if(is_list, as_tibble) %>%
# bind_cols needs tibbles to be in lists
map_if(is_tibble, list) %>%
# creates nested dataframe
bind_cols()
So, this should get you what you're looking for so long as my above assumptions are correct.
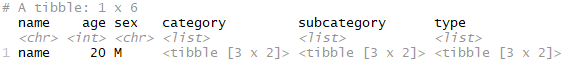
thanks Mr @olyerickson and Mr @ttrodrigz
both your suggestion helped me a lot.
thanks again for your time and effort..
here is my Expectation
as @ttrodrigz mentioned
Hi @pillai,
This seems like an odd way of storing the data. But, if I'm understanding you correctly that you want all of those nested dataframes into one long character string, then you can create a function which collapses them together and map that function to each of the nested dataframes. Then, collapse those three columns into one string.
For example:
make_string <- function(x) {
# creates a new column by pasting id and loc together
# pull extracts the new variable as a character vector
# finally, smush it all together
x %>%
mutate(new_var = paste(id, loc, sep = "-")) %>%
pull(new_var) %>%
paste(collapse = ", ")
}
# map the make_string function to each of the nested dataframes
your_df %>%
mutate(
category = map_chr(category, make_string),
subcategory = map_chr(subcategory, make_string),
type = map_chr(type, make_string),
your_str = paste(category,
subcategory,
type,
sep = ", ")) %>%
select(name, age, sex, your_str)
Is this what you were looking for? Again, I question whether this is the best way of storing the information found in your various sublevels, but I'm not privy to the context of the problem at hand.
Thanks Mr. @ttrodrigz
below is the conversion i'm looking for.
"user_master" : [
{ "ID": "ID101", "clasification": [{ "id": 1001, "loc": ["A1", "A2"] }, { "id": 1002, "loc": ["B1", "C2"] }] },
{ "ID": "ID102", "clasification": [{ "id": 2001, "loc": ["C1", "A2"] }, { "id": 3002, "loc": ["C1", "C2"] }] },
{ "ID": "ID103", "clasification": [{ "id": 1001, "loc": ["A1", "C1"] }, { "id": 1002, "loc": ["B1", "C1"] }] }
]
"collection": [
{ "r_num": 1, "ID": "ID101", "name: "n1", "loc":"A1", "clasif": ?},
{ "r_num": 2, "ID": "ID101", "name: "n1", "loc":"C1", "clasif": ?},
{ "r_num": 3, "ID": "ID102", "name: "n2", "loc":"B1", "clasif": ?},
{ "r_num": 4, "ID": "ID102", "name: "n2", "loc":"C1", "clasif": ?},
{ "r_num": 5, "ID": "ID103", "name: "n3", "loc":"A2", "clasif": ?},
]
i need to derive the Clasif field from user_master
collect all "clasification$id" where "collection$loc" %in% "clasification.loc"
for eg.
the result "collection" should look like
"collection": [
{ "r_num": 1, "ID": "ID101", "name: "n1", "loc":"A1", "clasif": "1001"},
{ "r_num": 2, "ID": "ID101", "name: "n1", "loc":"C2", "clasif": "3002"},
{ "r_num": 3, "ID": "ID102", "name: "n2", "loc":"B1", "clasif": ""},
{ "r_num": 4, "ID": "ID102", "name: "n2", "loc":"C1", "clasif": "2001, 3002"},
{ "r_num": 5, "ID": "ID103", "name: "n3", "loc":"A2", "clasif": ""},
}
this is exactly the data i have when i load data from mongolite
no i need to remove the list with string concatenation