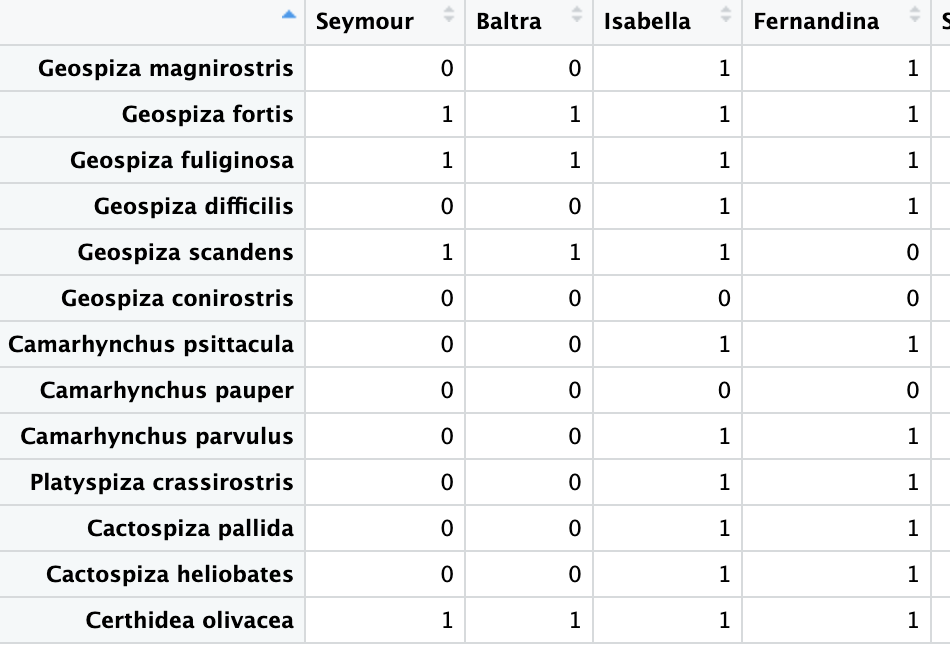
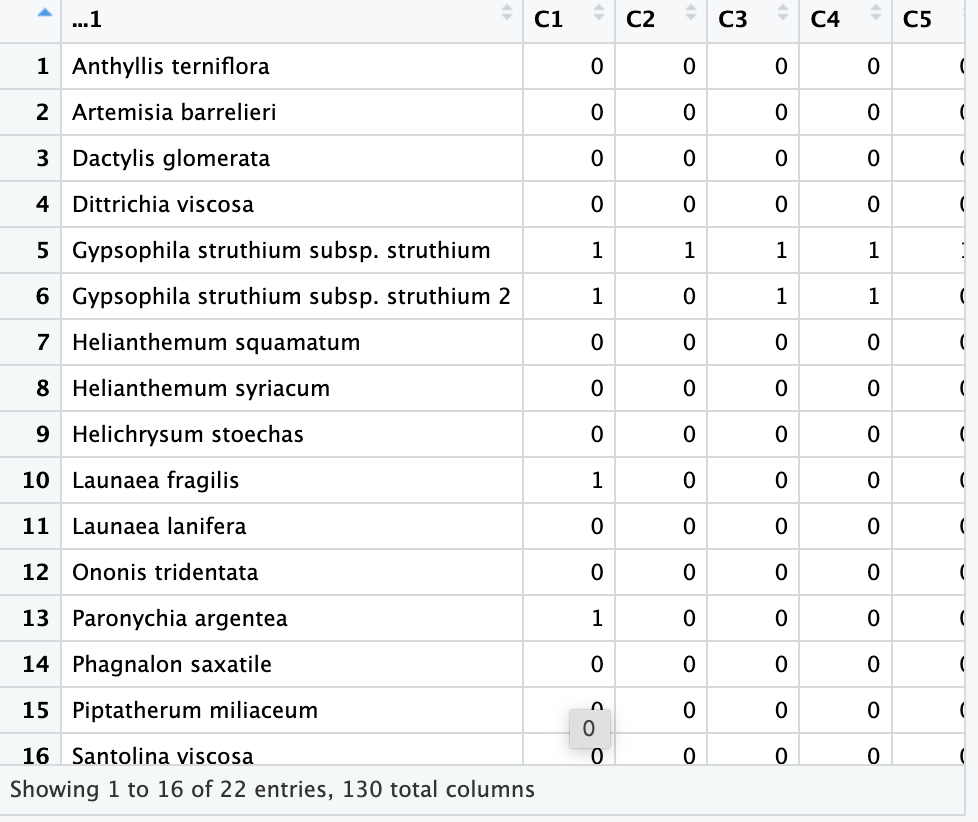
I am trying to import my excel file with a data set for a species cooccurrence analysis. I do not know how to import the data set so that the species names appear as the row titles instead of being listed in the first column.
I am going to attach an example screenshot for reference.
I am new to rstudio, so any information may help. Thanks.
Thank you for providing "before" and "after" comparisons, which are very helpful for folks trying to help you troubleshoot. Another important element to share is the code you used, which you can share by copying it and pasting it here between a pair of triple backticks, like this:
To add to @ dromano's point, if possible some sample data would help. If the data is not confidential, would it be possible to upload it to a file-sharing service such as Dropbox or Mediafire where readers here could download it?
I have not used Excel in years but that first screenshot suggests you have some kind of sorted table. If so what happens if it unsorted?
Tibble does not support rownames,you have to turned it into dataframe and then set the row name, provide your code so we can have a deep insight into the problem
It looks like this imported as best as one might hope; naturally the first column of the excel has been read in as a column (and not rownames); the only potential issue is that of the name for the column itself that holds that info.
your dataframe would naturally want column names to come from the 1st row of the excel you are reading. if there isn't valid name then one will be created, you got gifted the unique name ...1 which at least is communicating that it was the first column of the excel.
I think a simple dplyr::rename() would do the job to have it be another name. perhaps plant_name would be a good choice.
Thanks, @JCU27 , and a as a follow-up to @nirgrahamuk 's observations, would you be able to share a screenshot of the open Excel file, meaning open in Excel? It might help to see the first few rows and colulmns of the raw data, too.