Hi,
I did a logistic Regression and trying to plot it now. However, I do not find a way to plot it nicely. I'm not very familiar with R so I'm first trying to do it without interaction effects and just one variable.
Here is my data:
> dput(head(Wahl2013))
structure(list(Wahlbeteiligung = structure(c(1L, 1L, 1L, 1L,
1L, 1L), .Label = c("ja, habe gewaehlt", "nein, habe nicht gewaehlt"
), class = "factor"), Geschlecht = structure(c(2L, 2L, 1L, 1L,
1L, 1L), .Label = c("0", "1"), class = "factor"), Gebj = c(4L,
1L, 1L, 1L, 2L, 2L), Zweitstimme = c(1, 0, 0, 0, 0, 0), eig.Pst.Klima = c(4,
6, 7, 5, 5, 4), Salienz.Klima = c(1, 4, 4, 3, 2, 3), Bildung = c(3L,
3L, 1L, 3L, 2L, 1L), Atomenergie = c(3, 3, 3, 5, 3, 1)), na.action = structure(c(`2` = 2L,
`11` = 11L, `22` = 22L, `29` = 29L, `50` = 50L, `58` = 58L, `72` = 72L,
`76` = 76L, `77` = 77L, `85` = 85L, `96` = 96L, `108` = 108L,
`112` = 112L, `119` = 119L, `120` = 120L, `124` = 124L, `125` = 125L,
`130` = 130L, `142` = 142L, `143` = 143L, `151` = 151L, `160` = 160L,
`175` = 175L, `183` = 183L, `190` = 190L, `196` = 196L, `219` = 219L,
`229` = 229L, `234` = 234L, `238` = 238L, `243` = 243L, `248` = 248L,
`261` = 261L, `269` = 269L, `277` = 277L, `279` = 279L, `285` = 285L,
`286` = 286L, `287` = 287L, `311` = 311L, `313` = 313L, `319` = 319L,
`324` = 324L, `331` = 331L, `334` = 334L, `347` = 347L, `348` = 348L,
`351` = 351L, `352` = 352L, `359` = 359L, `368` = 368L, `373` = 373L,
`374` = 374L, `380` = 380L, `385` = 385L, `391` = 391L, `398` = 398L,
`410` = 410L, `412` = 412L, `422` = 422L, `423` = 423L, `434` = 434L,
`435` = 435L, `442` = 442L, `449` = 449L, `453` = 453L, `462` = 462L,
`463` = 463L, `466` = 466L, `473` = 473L, `483` = 483L, `484` = 484L,
`534` = 534L, `546` = 546L, `547` = 547L, `554` = 554L, `561` = 561L,
`568` = 568L, `573` = 573L, `583` = 583L, `596` = 596L, `612` = 612L,
`618` = 618L, `619` = 619L, `625` = 625L, `638` = 638L, `645` = 645L,
`677` = 677L, `692` = 692L, `726` = 726L, `734` = 734L, `738` = 738L,
`741` = 741L, `751` = 751L, `759` = 759L, `767` = 767L, `768` = 768L,
`770` = 770L, `774` = 774L, `784` = 784L, `792` = 792L, `793` = 793L,
`800` = 800L, `805` = 805L, `821` = 821L, `834` = 834L, `857` = 857L,
`867` = 867L, `869` = 869L, `877` = 877L, `895` = 895L, `896` = 896L,
`898` = 898L, `912` = 912L, `918` = 918L, `925` = 925L, `928` = 928L,
`931` = 931L, `939` = 939L, `946` = 946L, `949` = 949L, `956` = 956L,
`1001` = 1001L, `1009` = 1009L, `1016` = 1016L, `1018` = 1018L,
`1019` = 1019L, `1031` = 1031L, `1032` = 1032L, `1054` = 1054L,
`1058` = 1058L, `1062` = 1062L, `1063` = 1063L, `1068` = 1068L,
`1089` = 1089L, `1090` = 1090L, `1101` = 1101L, `1102` = 1102L,
`1121` = 1121L, `1154` = 1154L, `1156` = 1156L, `1162` = 1162L,
`1170` = 1170L, `1174` = 1174L, `1181` = 1181L, `1182` = 1182L,
`1183` = 1183L, `1191` = 1191L, `1196` = 1196L, `1201` = 1201L,
`1215` = 1215L, `1233` = 1233L, `1267` = 1267L, `1270` = 1270L,
`1294` = 1294L, `1297` = 1297L, `1305` = 1305L, `1315` = 1315L,
`1330` = 1330L, `1335` = 1335L, `1338` = 1338L, `1340` = 1340L,
`1345` = 1345L, `1352` = 1352L, `1370` = 1370L, `1373` = 1373L,
`1379` = 1379L, `1380` = 1380L, `1400` = 1400L, `1410` = 1410L,
`1427` = 1427L, `1438` = 1438L, `1439` = 1439L, `1440` = 1440L,
`1444` = 1444L, `1447` = 1447L, `1468` = 1468L, `1469` = 1469L,
`1473` = 1473L, `1485` = 1485L, `1486` = 1486L, `1490` = 1490L,
`1498` = 1498L, `1499` = 1499L, `1500` = 1500L, `1503` = 1503L,
`1506` = 1506L, `1516` = 1516L, `1520` = 1520L, `1522` = 1522L,
`1536` = 1536L, `1545` = 1545L, `1557` = 1557L, `1565` = 1565L,
`1569` = 1569L, `1576` = 1576L, `1577` = 1577L, `1579` = 1579L,
`1586` = 1586L, `1596` = 1596L), class = "omit"), row.names = c(1L,
3L, 4L, 5L, 6L, 7L), class = "data.frame")
model3 <- glm(Zweitstimme ~ Atomenergie, data = Wahl2013)
> summary(model3)
Call:
glm(formula = Zweitstimme ~ Atomenergie, data = Wahl2013)
Deviance Residuals:
Min 1Q Median 3Q Max
-0.17189 -0.12128 -0.07067 -0.02007 1.03054
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.081152 0.022555 -3.598 0.000332 ***
Atomenergie 0.050609 0.006139 8.244 3.81e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for gaussian family taken to be 0.08119716)
Null deviance: 118.71 on 1395 degrees of freedom
Residual deviance: 113.19 on 1394 degrees of freedom
AIC: 460.49
Number of Fisher Scoring iterations: 2
> ggplot(Wahl2013, aes(x=Atomenergie, y=Zweitstimme)) +
+ geom_point(shape=1, position=position_jitter(width=.05,height=.05)) +
+ stat_smooth(method="glm", method.args=list(family="binomial"), se=FALSE)
This Looks like this:
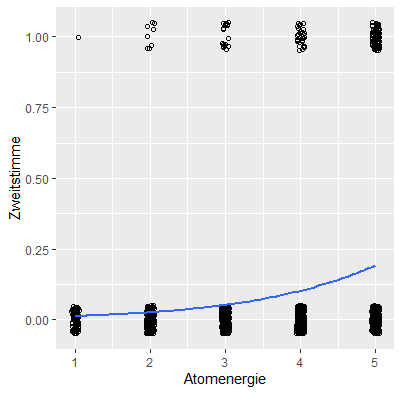
I do not find a way, to make it look better. Thanks for help!