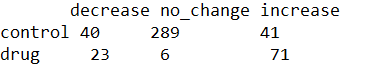Hi all, I feel a little stupid making this post as I am completely new to not only R but coding in general. I am struggling to perform a basic chi-squared test on some data. I have downloaded R and have made progress with a few simple functions, but I am otherwise very clueless. I think that I am supposed to use the > chisq.test(tbl) command, however I am not even sure how to insert my data and then turn it into a table! I have watched online tutorials, but the data used in their examples seem fundamentally different, so I'm not sure how to set it up for my own.
This is what my data looks like, it is a .txt file.
It describes two sets of people; treated group "drug" comprised of 100 people who were given a treatment and a larger "control" group who match age/gender profile of the "drug" group (also given the treatment). The numbers show how many people experienced either decrease/no change/increase in blood sugar levels after taking the drug and my aim is to find out whether this treatment effects blood sugar levels.
I am not sure if I am just overthinking this and can simply import the table as it is and literally plug it into the chi squared command. Any help would be really, really appreciated!
Here are two ways to get your data into an object that you can run the test on. In the first, I typed your data into a csv file and read it with read.csv(). Note that I used the first column as row names by setting row.names = 1 when I called read.csv(). In the second, I made a matrix of the data, typing it directly into the R code.
Ah, thank you so much!! I'll go with the second as it seems a bit simpler.
Like I said, I'm totally unfamiliar with coding; when I perform the chi-squared test on this table, does it automatically know what to compare (in this case, the control group to the treatment group rows)? I would have thought this would have to be specified manually, somehow? Just seems suspiciously straightforward, unless that's actually how it's done?
All the chi-squared test looks at is the counts within the cells of the table and whether the observed variations are likely to be due to chance. Any meaning assigned to the cells has no influence on the test. There is a nice example in the Wikipedia article in the section Example Chi-squared Test For Categorical Data. In particular, the test does not give you any information about where in the data the "unexpected" counts appear. If there are many rows and columns, that might not be obvious.